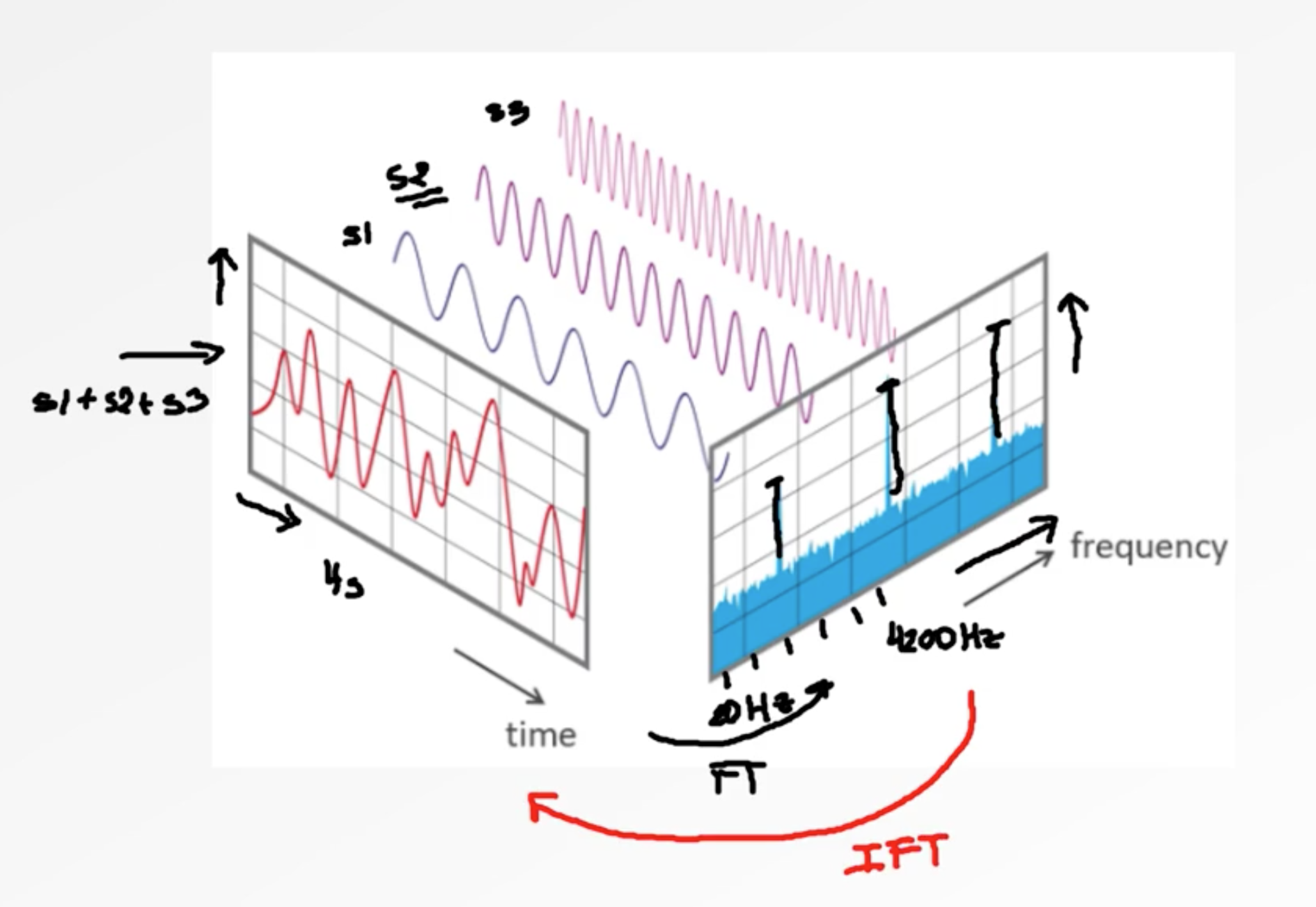
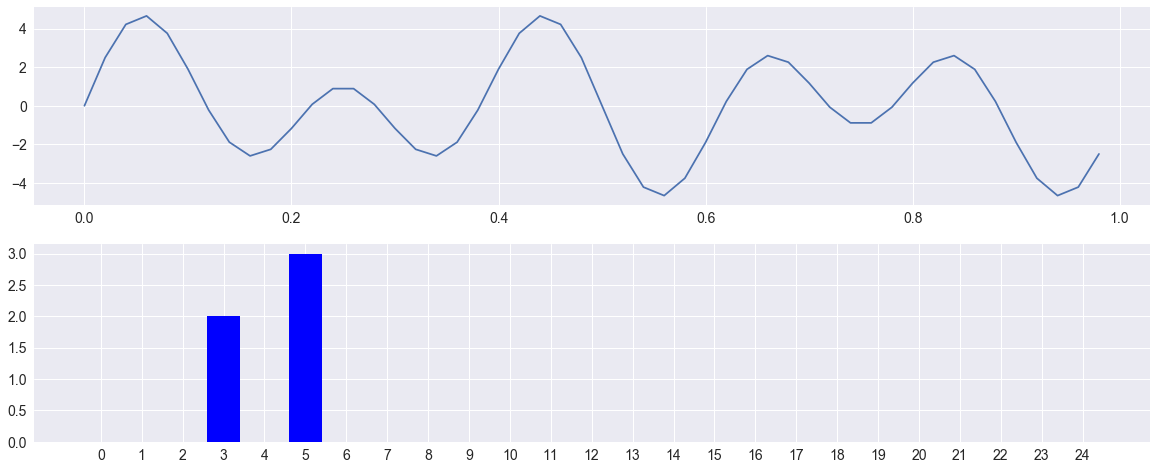
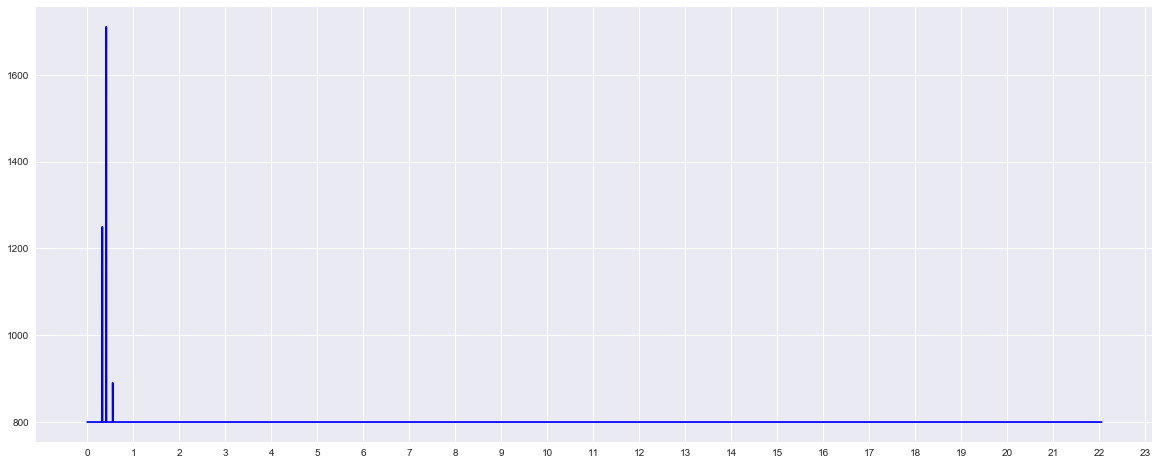
The Fourier transform (FT) decomposes a function (often a function of time, or a signal) into its constituent frequencies.
One motivation for the Fourier transform comes from the study of Fourier series. In the study of Fourier series, complicated but periodic functions are written as the sum of simple waves mathematically represented by sines and cosines. The Fourier transform is an extension of the Fourier series that results when the period of the represented function is lengthened and allowed to approach infinity.
The Fourier transform of a function f is traditionally denoted \(\hat{f}\), by adding a circumflex to the symbol of the function. There are several common conventions for defining the Fourier transform of an integrable function
\[\hat{f}(\xi) = \int_{-\infty}^{\infty} f(x)\ e^{-2\pi i x \xi}\,dx\]
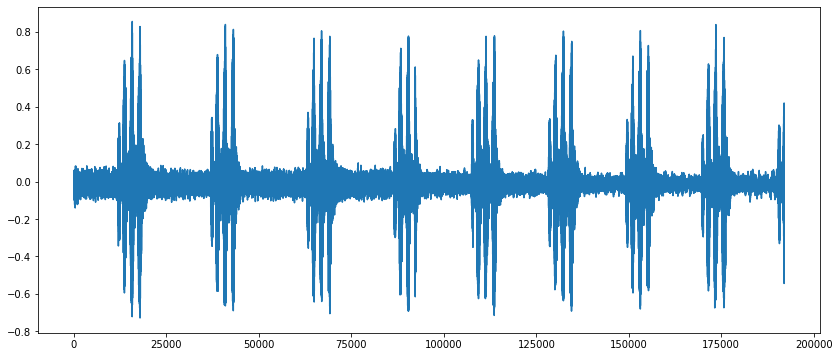
If we want to describe a signal, we need three things : - The frequency of the signal which shows, how many occurrences in the period we have. - Amplitude which shows the height of the signal or in other terms the strength of the signal. - Phase shift as to where does the signal starts.
""" (C) 2018 Nikolay Manchev This work is licensed under the Creative Commons Attribution 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/. """
""" (C) 2018 Nikolay Manchev This work is licensed under the Creative Commons Attribution 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/. """
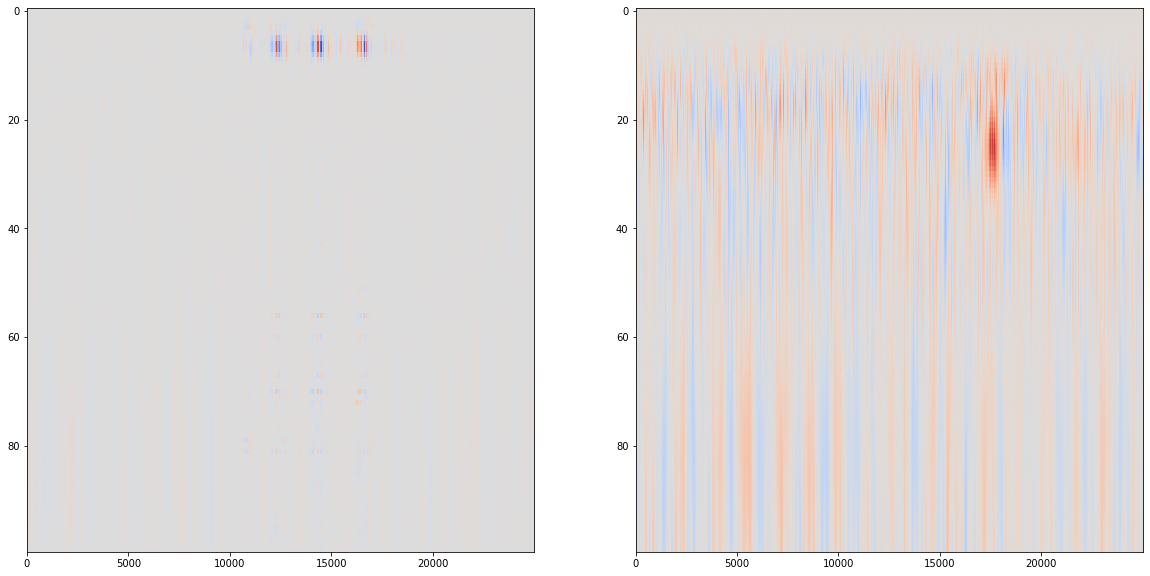
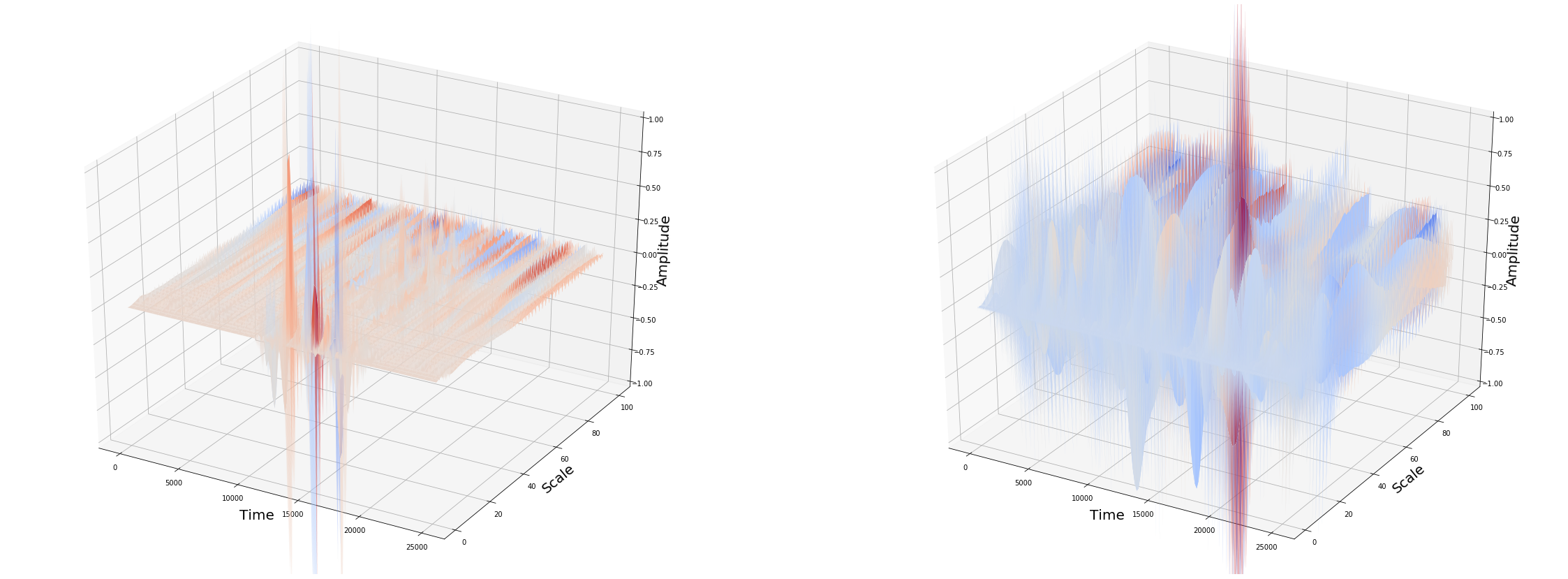
Wavelets have some slight benefits over Fourier transforms in reducing computations when examining specific frequencies. However, they are rarely more sensitive, and indeed, the common Morlet wavelet is mathematically identical to a short-time Fourier transform using a Gaussian window function. The exception is when searching for signals of a known, non-sinusoidal shape (e.g., heartbeats); in that case, using matched wavelets can outperform standard STFT/Morlet analyses.
import os import sys import types import ibm_boto3
import pandas as pd import numpy as np import matplotlib.pyplot as plt
from io import BytesIO from zipfile import ZipFile from botocore.client import Config
from sklearn.model_selection import train_test_split from sklearn import svm from sklearn.metrics import accuracy_score
import soundfile as sf import librosa
import pywt
%matplotlib inline
1
zip_file = ZipFile("audio_data.zip")
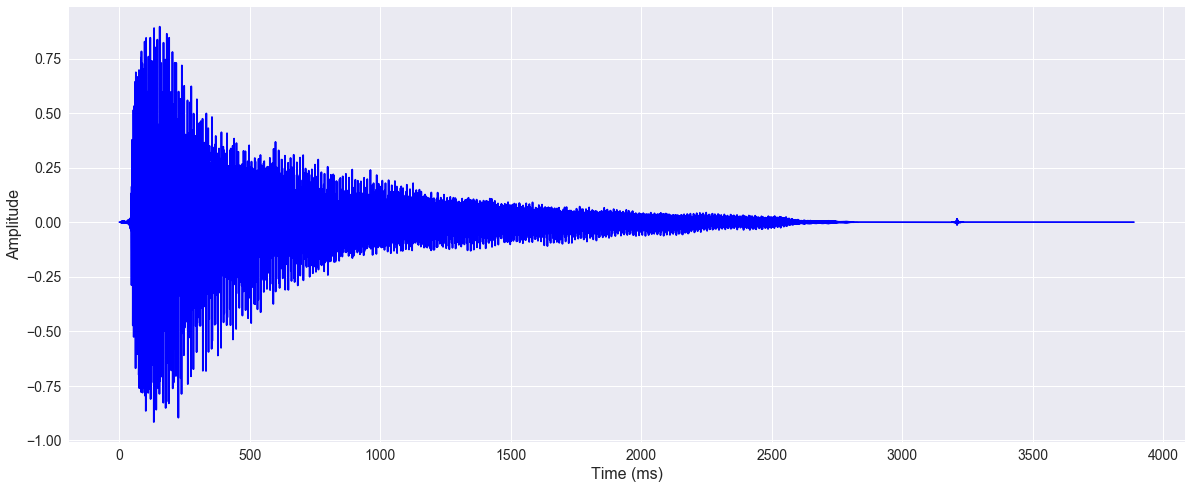
The data used for this demonstration comes from the Urban Sounds Dataset. This dataset and its taxonomy is presented in J. Salamon, C. Jacoby and J. P. Bello, A Dataset and Taxonomy for Urban Sound Research, 22nd ACM International Conference on Multimedia, Orlando USA, Nov. 2014.
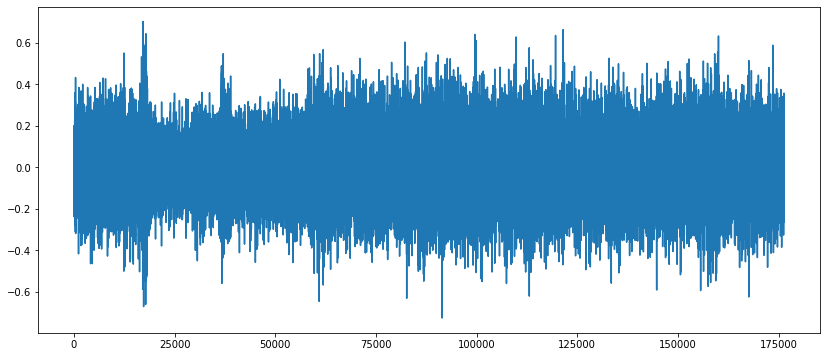
For simplicity the dataset is sampled and a subset of 20 audio clips from two categories are used - air conditioner (AC) and drill.
# for index in range(len(audio_data)): # if (sampling_rate[index] == 48000): # audio_data[index] = librosa.resample(audio_data[index], 48000, 44100) # sampling_rate[index] = 44100
1 2 3 4 5 6 7
defto_mono(data): if data.ndim > 1: data = np.mean(data, axis=1) return data
for index inrange(len(audio_data)): audio_data[index] = to_mono(audio_data[index])
for ind inrange(len(audio_data)): print('.', end='') coeff, freqs = pywt.cwt(audio_data[ind][:25000], scales, 'morl') features = np.vstack([features, pca.fit_transform(coeff).flatten()])