GRU
RNNs have been found to perform better with the use of more complex units for activation. Here, we discuss the use of a gated activation function thereby modifying the RNN architecture. What motivates this? Well, although RNNs can theoretically capture long-term dependencies, they are very hard to actually train to do this. Gated recurrent units are designed in a manner to have more persistent memory thereby making it easier for RNNs to capture long-term dependencies. Let us see mathematically how a GRU uses \(h_{t−1}\) and \(x_t\) to generate the next hidden state ht. We will then dive into the intuition of this architecture.
\[\begin{aligned} & z_t = \sigma(W^{(z)}x_t + U^{(z)}h_{t-1}) & \text{(Update gate)} \\ & r_t = \sigma(W^{(r)}x_t + U^{(r)}h_{t-1}) & \text{(Reset gate)}\\ & \tilde{h_t} = tanh{r_t \circ Uh_{t-1} + Wx_t} & \text{(New memory)} \\ & h_t = (1 - z_t) \circ \tilde{h_t} + z_t \circ h_{t-1} & \text{(Hidden state)} \end{aligned}\]
The above equations can be thought of a GRU’s four fundamental operational stages and they have intuitive interpretations that make this model much more intellectually.
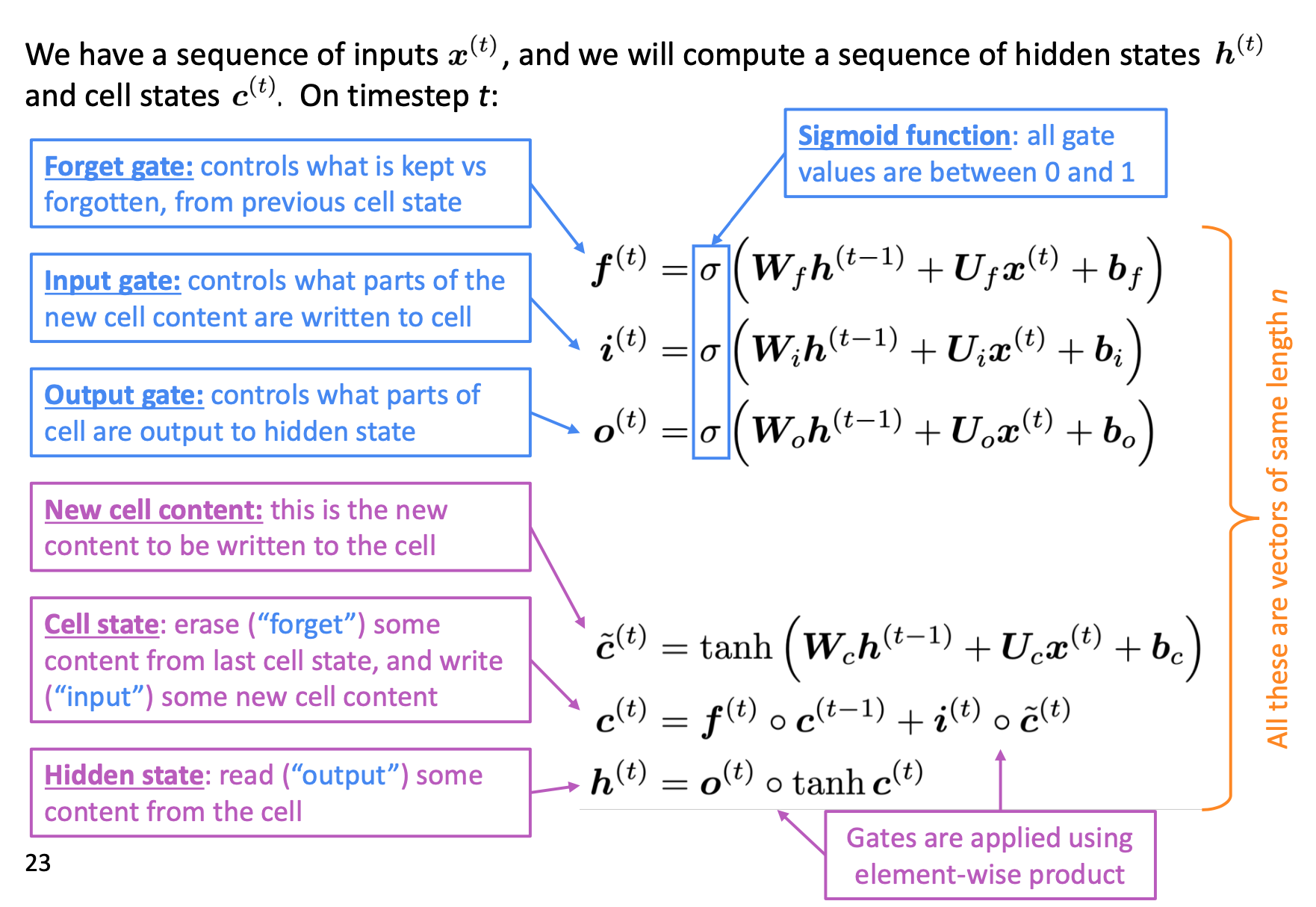
- Reset gate: controls what parts of previous hidden state are used to compute new content
- Update gate: controls what parts of hidden state are updated vs preserved
- New hidden state content: reset gate selects useful parts of prev hidden state. Use this and current input to compute new hidden content.
- Hidden state: update gate simultaneously controls what is kept from previous hidden state, and what is updated to new hidden state content
LSTM
Long-Short-Term-Memories are another type of complex activation unit that differ a little from GRUs. The motivation for using these is similar to those for GRUs however the architecture of such units does differ. Let us first take a look at the mathematical formulation of LSTM units before diving into the intuition behind this design:
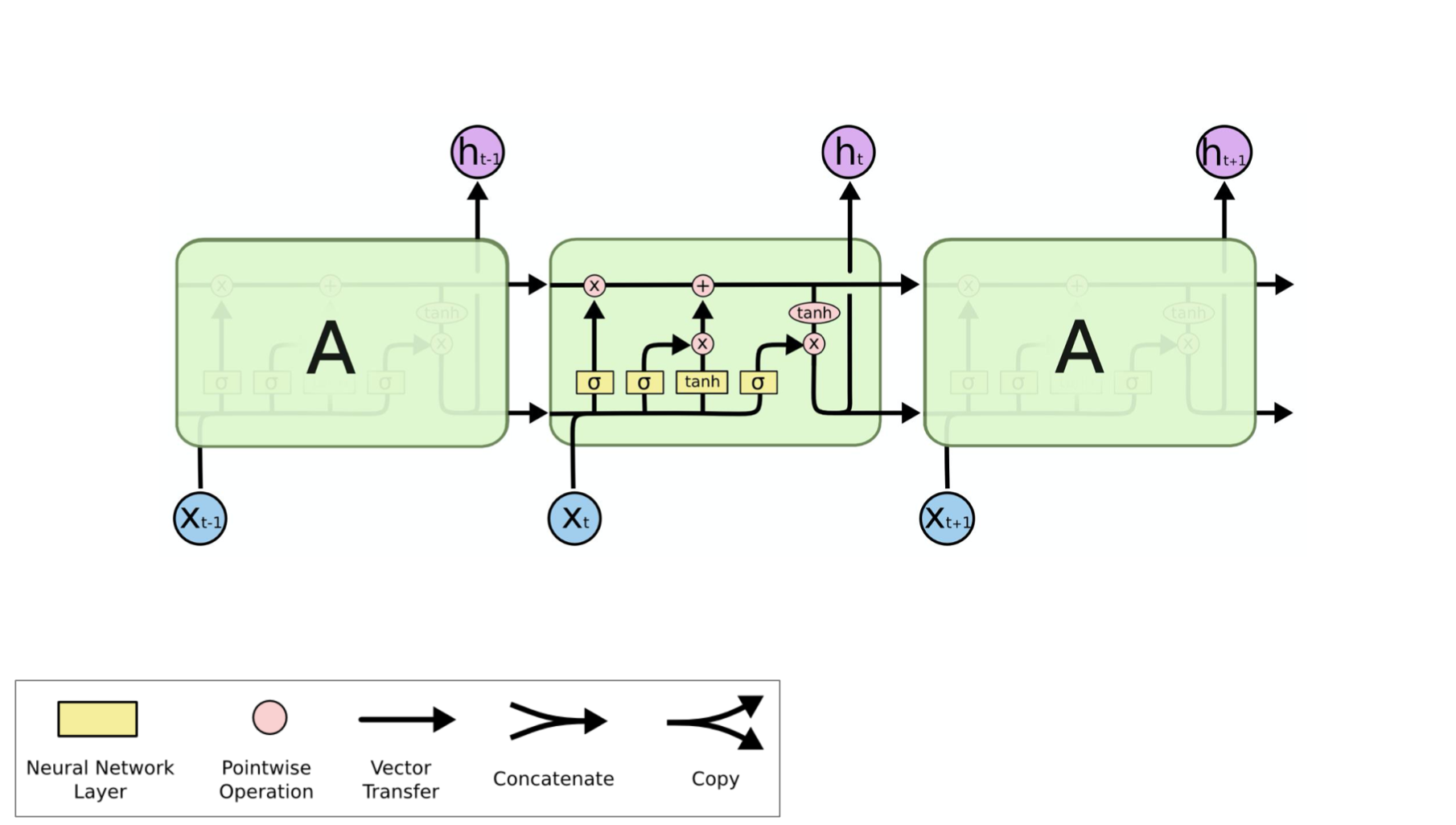
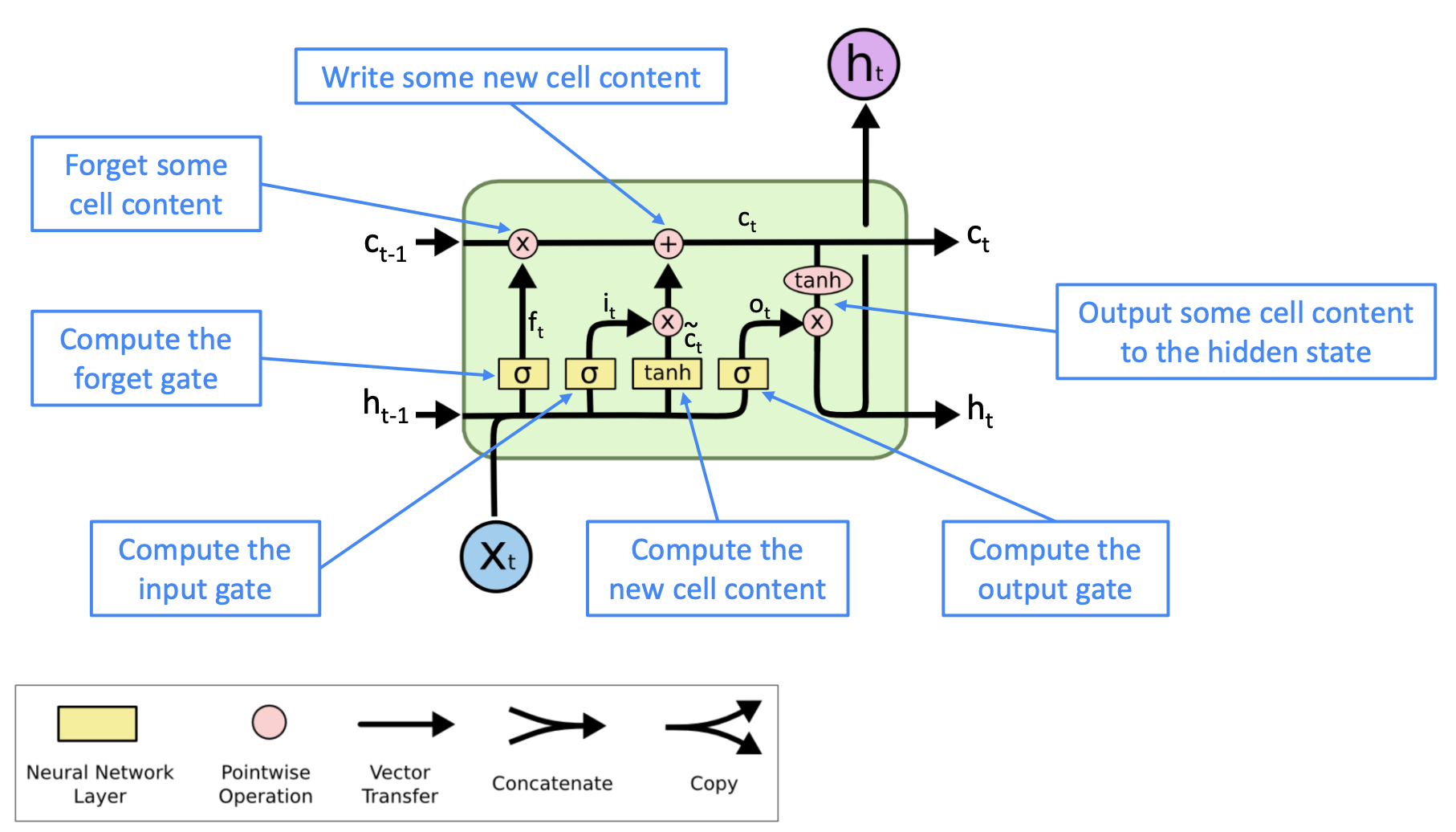
- The LSTM architecture makes it easier for the RNN to preserve information over many timesteps
- e.g. if the forget gate is set to remember everything on every timestep, then the info in the cell is preserved indefinitely
- By contrast, it’s harder for vanilla RNN to learn a recurrent weight matrix Wh that preserves info in hidden state
- LSTM doesn’t guarantee that there is no vanishing/exploding gradient, but it does provide an easier way for the model to learn long-distance dependencies.
LSTM vs GRU
- Researchers have proposed many gated RNN variants, but LSTM and GRU are the most widely-used
- The biggest difference is that GRU is quicker to compute and has fewer parameters
- There is no conclusive evidence that one consistently performs better than the other
- LSTM is a good default choice (especially if your data has particularly long dependencies, or you have lots of training data)
- Rule of thumb: start with LSTM, but switch to GRU if you want something more efficient
reference
- course slides and notes from cs224n (http://web.stanford.edu/class/cs224n/)