Reference from some lecture slides of INFSCI 2595 lectured by Dr. Mai Abdelhakim
Introduction
What is Machine Learning?
- Subfield of artificial intelligence
- Field of study that gives computers the ability to learn without being explicitly programmed
How can we build computer system that learn and improve with experience?
- Statistics make conclusions from data, and estimate reliability of conclusions
- Optimization and computing power to solve problems
Machine learns with respect to a particular task T, performance metric P and experience E, if the performance P on task T improves with experience E.
Why Machine Learning is Important
- Provide solution to complex problems that cannot be easily programmed
- Can adapt to new data
- Helps us to understand complicated phenomena
- Can outperform human performance
Machine Learning Algorithms
Supervised Learning
- Learn using labeled data (correct answers are given in learning phase)
- make predictions of previously unseen data
- Two types of problems
- Regression: Target values (Y) are continuous/quantitative
- Classification: Target values (Y) are discrete/finite/qualitative
Unsupervised Learning
- Clustering analysis
- Finding groups of similar users
- Detecting abnormal patterns
Machine Learning Models and Trade-offs
Why do we need a model? Why estimate f?
- Predictions: Make predictions for new inputs/features
- Inference: understand the way Y is affected by each features
- Which feature has stronger impact on the response?
- Is relation positive or negative
- Is the relationship linear or more complicated
How to estimate f?
- Parametric Approach
- First,assume function form
- Second, use training to fit the model
- Non-Parametric Approach
- No explicit form of function f is assumed
- Seek to estimate f as close as possible to the data points
Trade-off: Model Flexibility vs Model Interpretability
{kind=link}
Model Accuracy
- In regression setting, a common measure is mean squared error(MSE)
\[MSE = \frac{1}{n}\sum_{i=1}^{n}(y_{i} - \hat{f(x_{i})})^{2}\]
Overfitting and Underfitting
Two thing we need to avoid: - Overfitting: Building a model that is too complex, fits training data very well, but fail to generalize to new data (e.g. large test MSE) - Underfitting: build simple model that is unable to capture variability in data
- Simple models may not capture the variability in the data
- Complex models may not generalize
Bias-Variance Tradeoff
\[E(y_{0} - \hat{f(x_{0})})^2 = Var(\hat{f(x_{0})}) + [Bias(\hat{f(x_{0})})]^{2} + Var(\epsilon)\]
- Variance: amount by which \(\hat{f}\) changes if we made the estimation by different training set
- Bias: Errors from approximating real-life problems by a simpler model
- Classification Setting
- \(\hat{y_{0}} = \hat{f(x_{0})}\) is the predicted output class
- Test error rate: \[Average(I(y_{0} \neq \hat{y_{0}}))\]
Bayes classifier
- Bayes classifier assigns each observation to the most likely class given the feature values.
- Assign \(x_{0}\) to class ! that has largest \(Pr(Y= j|X = x_{0})\)
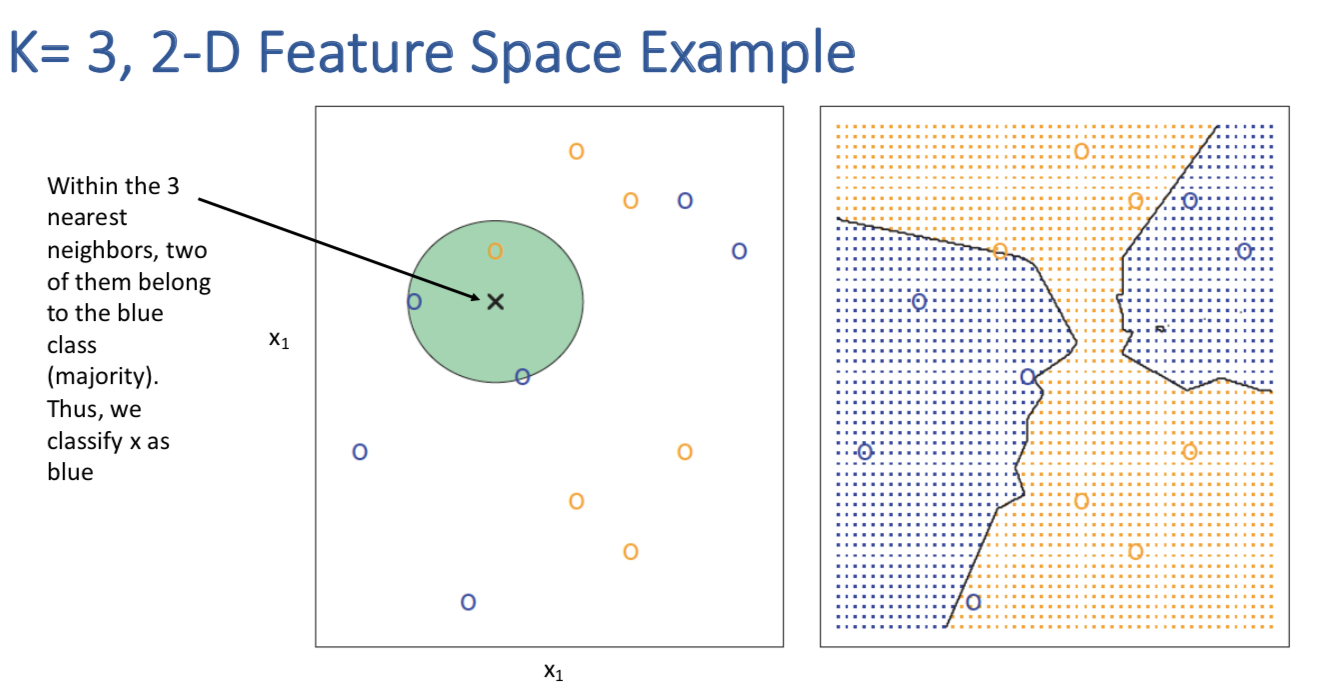
K-Nearest Neighbors
- Define a positive integer K
- For each test observation \(x_{0}\) , identify K points in the training data that are closest to \(x_{0}\) referred to as \(N_{0}\)
- Estimate the conditional probability for class j as fraction of points in \(N_{0}\) whose response values equal to j \[Pr(Y = j | X = x_{0}) = \frac{1}{k}\sum_{i \in N_{0}}I(y_{i} == j)\]
{kind=link}