Image-to-Image Translation with Conditional Adversarial Networks
- Category: Article
- Created: February 12, 2022 2:39 PM
- Status: Open
- URL: https://arxiv.org/pdf/1611.07004.pdf
- Updated: February 15, 2022 5:15 PM
Highlights
- We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems.
- As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
Intuition
- If we take a naive approach and ask the CNN to minimize the Euclidean distance between predicted and ground truth pix- els, it will tend to produce blurry results.
- It would be highly desirable if we could instead specify only a high-level goal, like “make the output indistinguishable from reality”, and then automatically learn a loss function appropriate for satisfying this goal.
Methods
Our generator we use a U-Net-based architecture, and for our discriminator we use a convolutional PatchGAN classifier, which only penalizes structure at the scale of image patches.
Loss function
The objective of a conditional GAN can be expressed as
\(\begin{aligned}\mathcal{L}_{c G A N}(G, D)=& \mathbb{E}_{x, y}[\log D(x, y)]+\\& \mathbb{E}_{x, z}[\log (1-D(x, G(x, z))]\end{aligned}\)
Previous approaches have found it beneficial to mix the GAN objective with a more traditional loss, such as L2 distance. The discriminator’s job remains unchanged, but the generator is tasked to not only fool the discriminator but also to be near the ground truth output in an L2 sense. We also explore this option, using L1 distance rather than L2 as L1 encourages less blurring:
\[ \mathcal{L}_{L 1}(G)=\mathbb{E}_{x, y, z}\left[\|y-G(x, z)\|_{1}\right] \]
\[ G^{*}=\arg \min _{G} \max _{D} \mathcal{L}_{c G A N}(G, D)+\lambda \mathcal{L}_{L 1}(G) \]
Generator
To give the generator a means to circumvent the bottle- neck for information like this, we add skip connections, following the general shape of a U-Net.
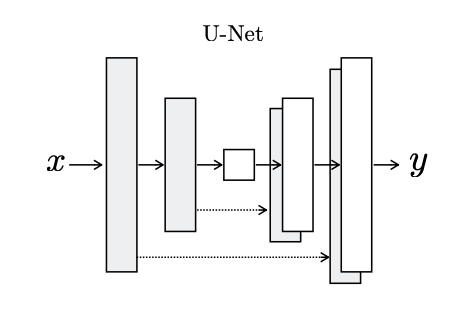
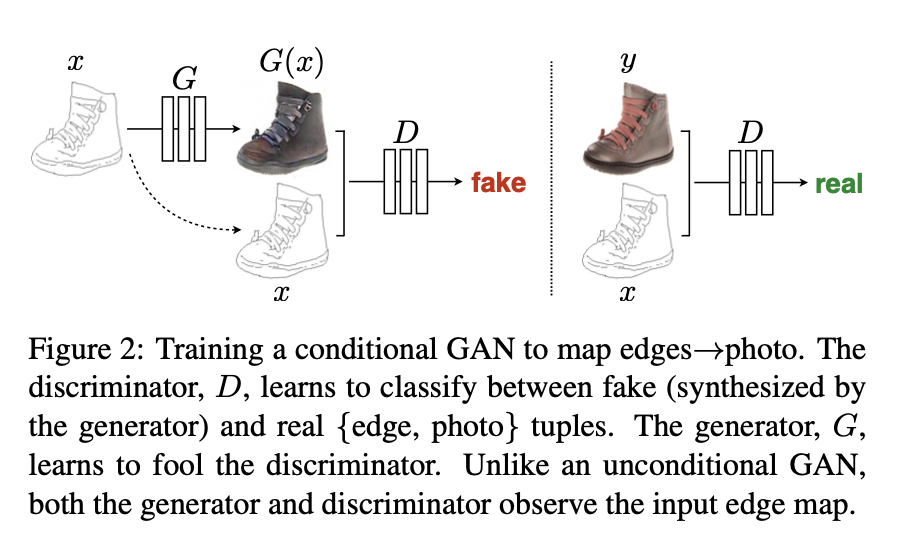
Discriminator (PatchGAN)
This motivates restricting the GAN discriminator to only model high-frequency structure, relying on an L1 term to force low-frequency correctness.
In order to model high-frequencies, it is sufficient to restrict our attention to the structure in local image patches. Therefore, we design a discriminator architecture – which we term a PatchGAN – that only penalizes structure at the scale of patches.
This discriminator tries to classify if each N × N patch in an image is real or fake. We run this discriminator convolution- ally across the image, averaging all responses to provide the ultimate output of D.
Code
1 | class Discriminator(nn.Module): |
1 | def get_gen_loss(gen, disc, real, condition, adv_criterion, recon_criterion, lambda_recon): |
1 | adv_criterion = nn.BCEWithLogitsLoss() |
Conclusion

The results in this paper suggest that conditional adversarial networks are a promising approach for many image- to-image translation tasks, especially those involving highly structured graphical outputs. These networks learn a loss adapted to the task and data at hand, which makes them applicable in a wide variety of settings.