KMeans++ Algorithm
- Smart initialization:
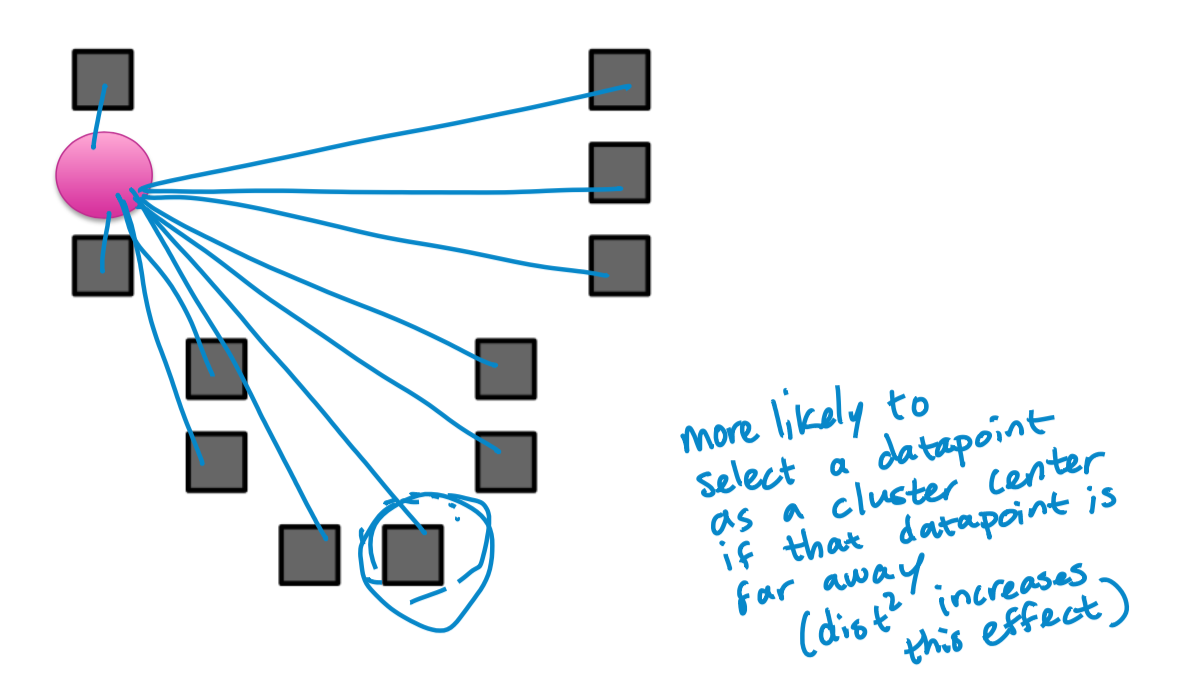
- Choose first cluster center uniformly at random from data points
- For each obs x, compute distance d(x) to nearest cluster center
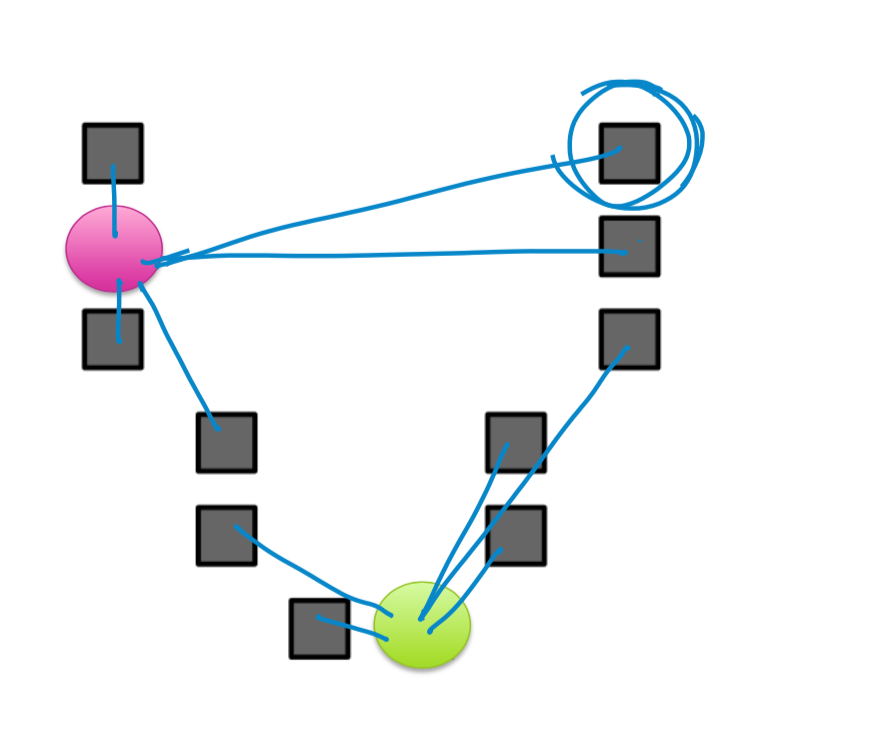
- Choose new cluster center from amongst data points, with probability of x being chosen proportional to d(x)2
- Repeat Steps 2 and 3 until k centers have been chosen
- Run the standard KMeans with centers got above
- Assign observations to closest cluster center
- Revise cluster centers as mean of assigned observations
- Repeat 1.+2. until convergence
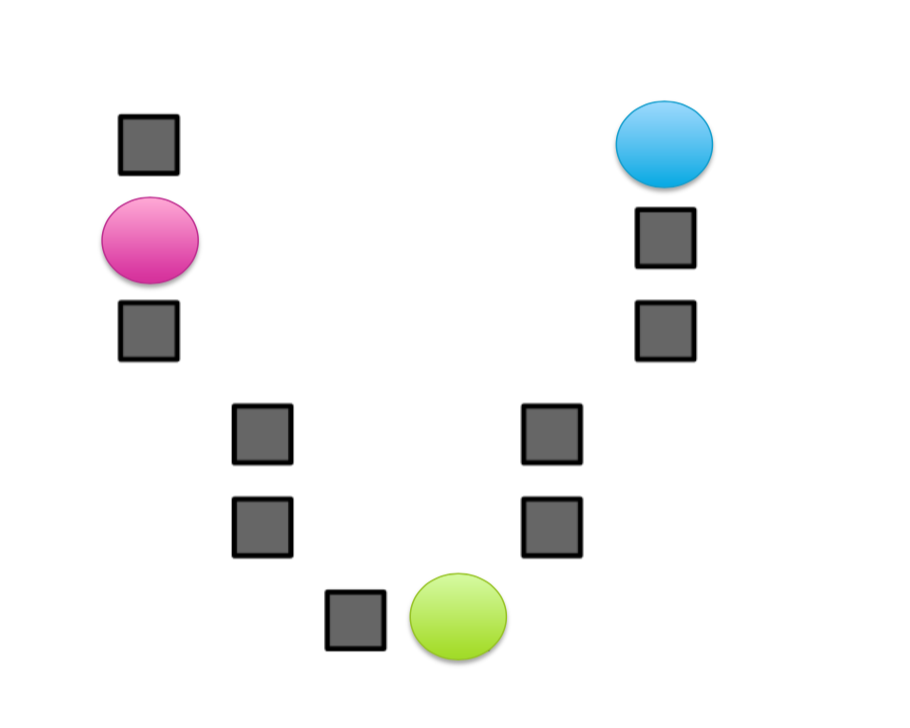
KMeans++ visualized
Elkan K-Means Algorithm (距离计算优化)
在传统的K-Means算法中,我们在每轮迭代时,要计算所有的样本点到所有的质心的距离,这样会比较的耗时。那么,对于距离的计算有没有能够简化的地方呢?elkan K-Means算法就是从这块入手加以改进。它的目标是减少不必要的距离的计算。那么哪些距离不需要计算呢?
elkan K-Means利用了两边之和大于等于第三边,以及两边之差小于第三边的三角形性质,来减少距离的计算。
- 对于一个样本点\(x\)和两个质心\(\mu_1\),\(\mu_2\).如果我们预先计算出了这两个质心之间的距离\(D(\mu_1,\mu_2)\),则如果计算发现 \(2D(x,\mu_1) \leq D(\mu_1,\mu_2)\), 我们可以得知 \(2D(x,\mu_1) \leq D(x,\mu_2)\),此时我们不需要再计算\(D(x,\mu_2)\),也就是说省了一步距离计算。
- 对于一个样本点\(x\)和两个质心\(\mu_1\),\(\mu_2\),我们可以得到 \(D(x,\mu_2) > max\lbrace 0, D(x,\mu_1) - D(\mu_1,\mu_2)\rbrace\)
MapReduce for scaling KMeans
What is MapReduce

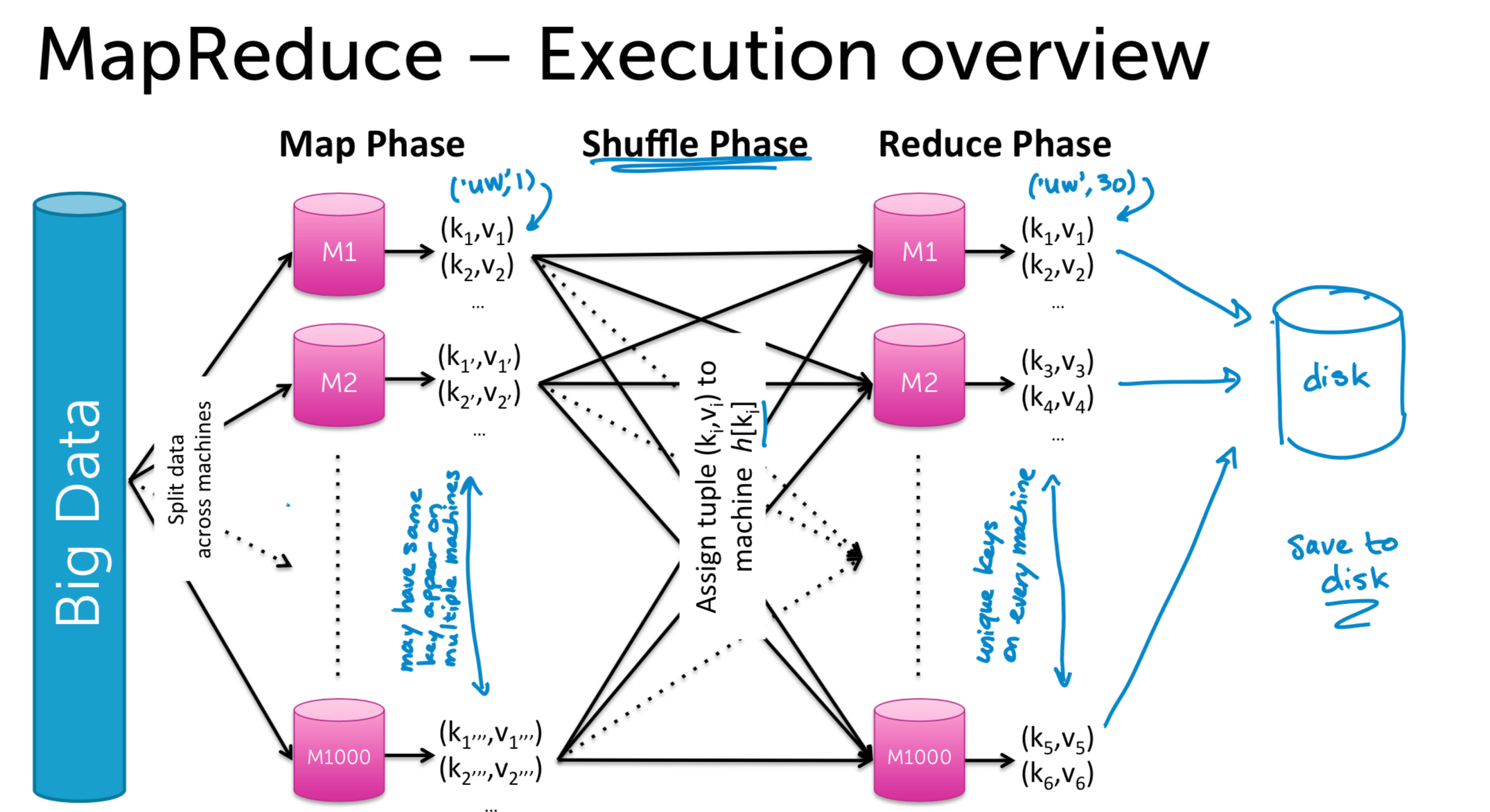
Scaling up KMeans via MapReduce
- Classify: Assign observations to closest cluster center \[z_i = \mathop{\arg\min}_{j}\Vert \mu_{j} - x_{j} \Vert^2_2\]
For each data point, given \((\mu_{j}, x_{i} )\), \(emit(z_i, x_i)\)
- Recenter: Revise cluster centers as mean of assigned observations
\[\mu_j = \frac{1}{n_j}\sum\limits_{i:z_i = k} x_i\]
Reduce: Average over all points in cluster \(j(z_j = k)\)