What hypothesis set can we use?
A Simple Hypothesis Set: the "Perceptron"
- Perceptron in \(\mathbb{R}^2\)
\[h(x) = sign(w_0 + w_1x_1 + w_2x_2)\] 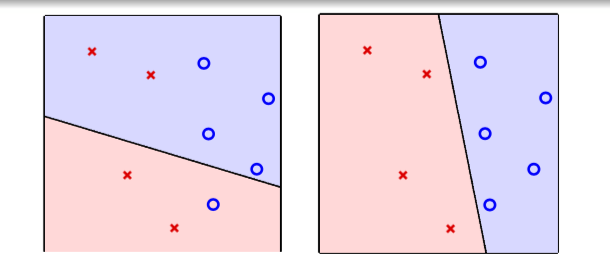
- features x: points on the plane (or points in \(\mathbb{R}^d\) )
- labels y: (+1), × (-1)
- hypothesis h: lines (or hyperplanes in \(\mathbb{R}^d\) ),positive on one side of a line, negative on the other side
- different line classifies simples differently
perceptrons <=> linear (binary) classifiers
Select g from \(\mathscr{H}\)
- want: \(g \approx f\) (hard when f unknown)
- almost necessary: \(g \approx f\) on D, ideally \(g(x_n) = f(x_n) = y_n\)
- difficult: H is of infinite size
- idea: start from some \(g_0\), and correct its mistakes on \(D\)
Perceptron Learning Algorithm

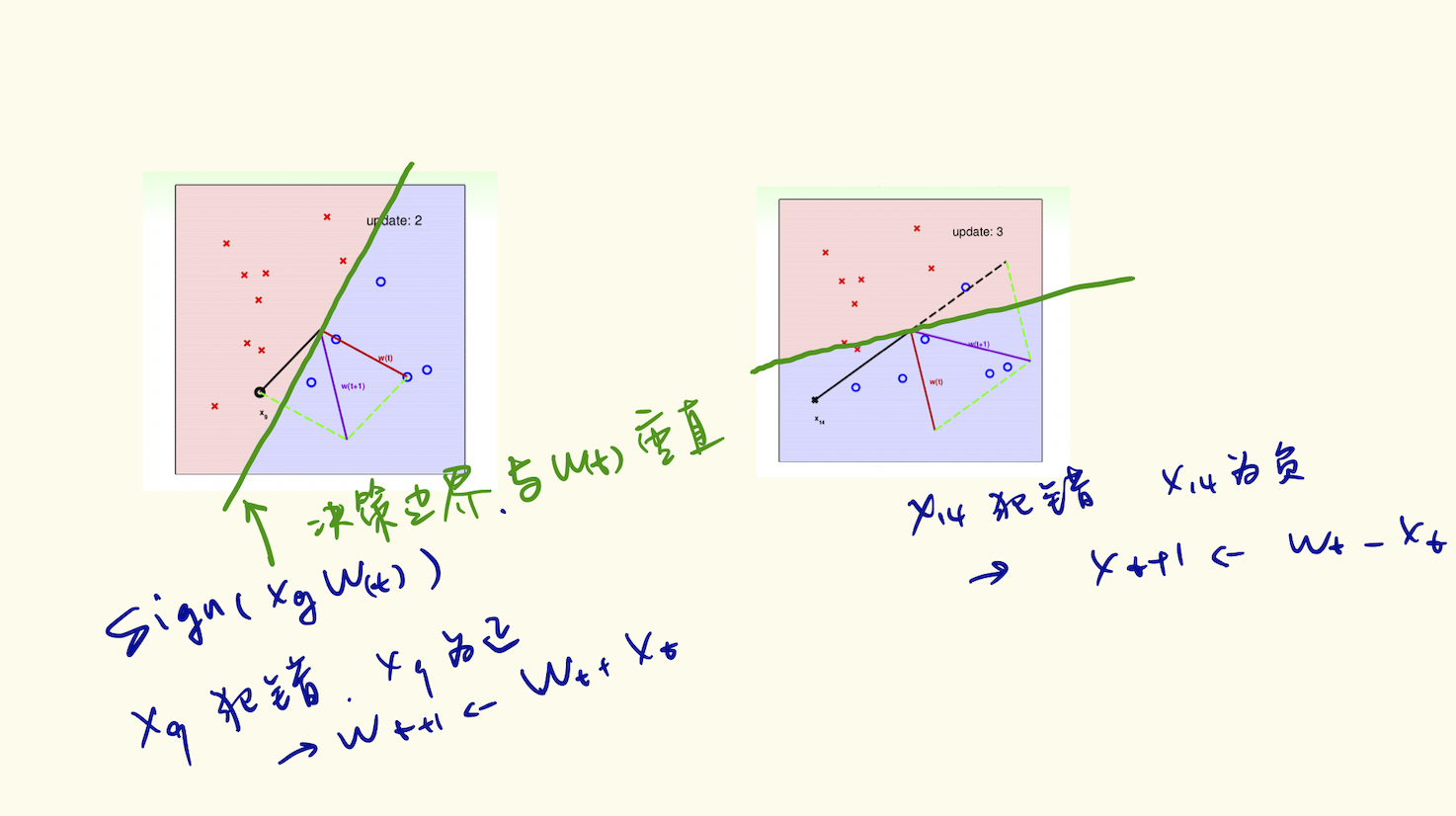
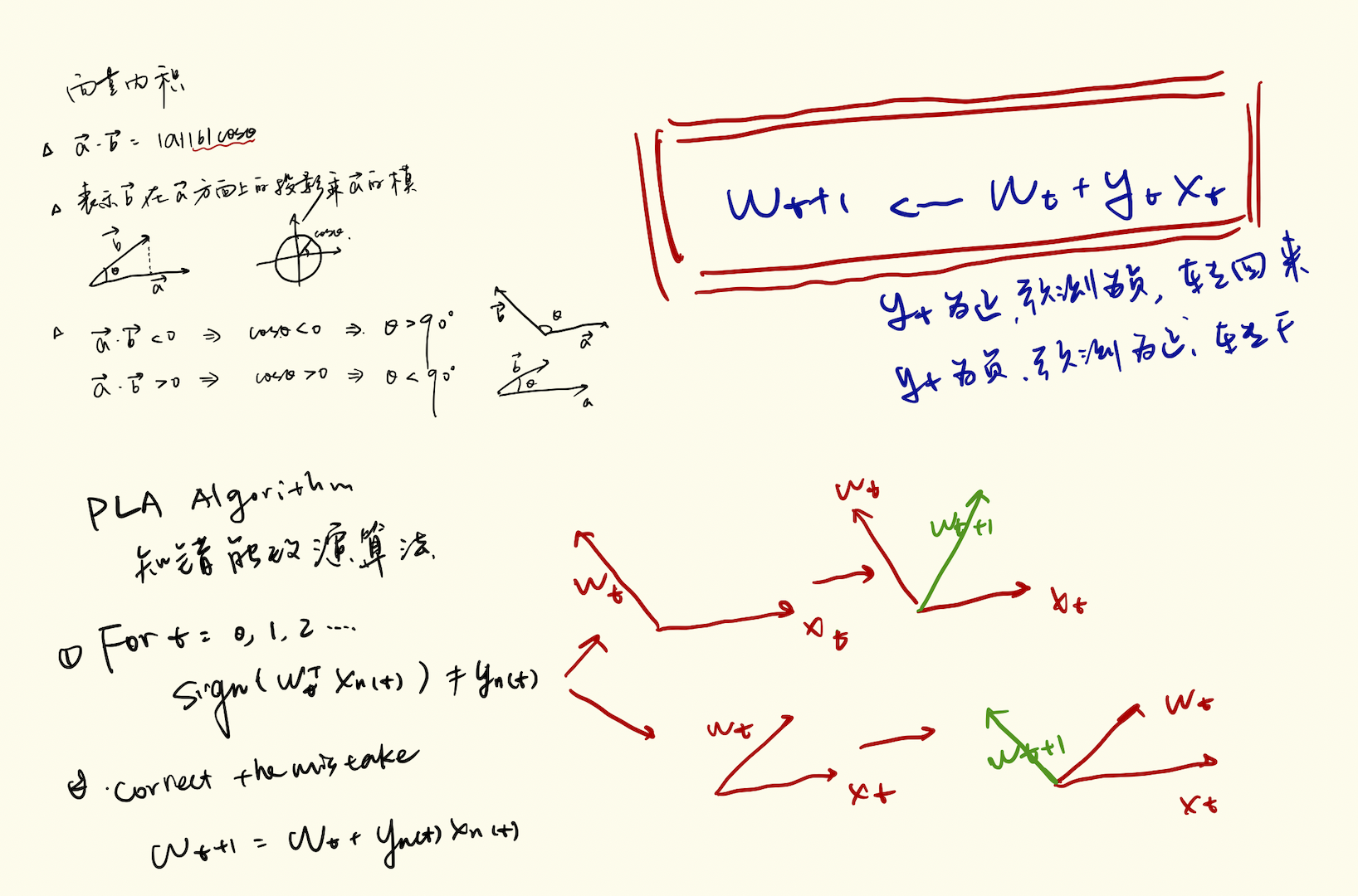
- if PLA halts (i.e. no more mistakes), (necessary condition) \(D\) allows some w to make no mistake
- call such \(D\) linear separable
- as long as linear separable and correct by mistake
- inner product of \(w_f\) and \(w_t\) grows fast; length of wt grows slowly
- PLA ‘lines’ are more and more aligned with \(w_f \rightarrow halts\)
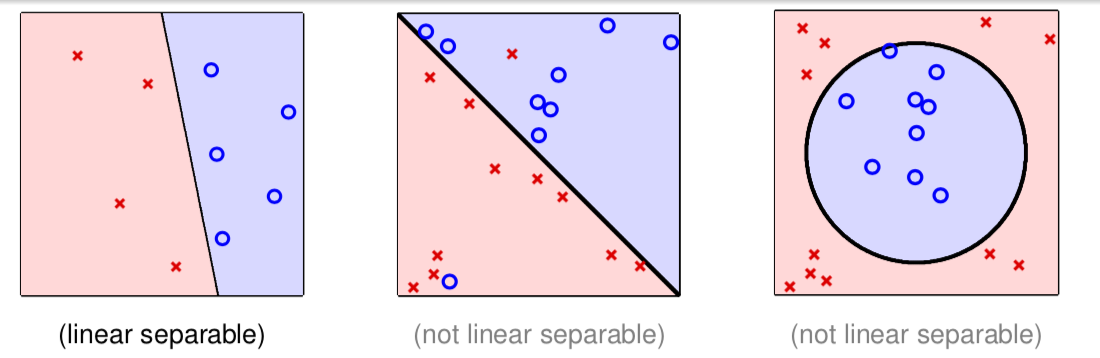
Line with Noise Tolerance
\(D\) is not linear separable?

Pocket Algorithm
Find the best weights in pocket until enough iterations

Question
Since we do not know whether D is linear separable in advance, we may decide to just go with pocket instead of PLA. If D is actually linear separable, what’s the difference between the two?
1 pocket on D is slower than PLA
2 pocket on D is faster than PLA
3 pocket on D returns a better g in approximating f than PLA
4 pocket on D returns a worse g in approximating f than PLA
answer: Because pocket need to check whether \(w_{t+1}\) is better than \(\hat{w}\) in each iteration, it is slower than PLA. On linear separable D, \(w_{POCKET}\) is the same as \(w_{PLA}\), both making no mistakes.