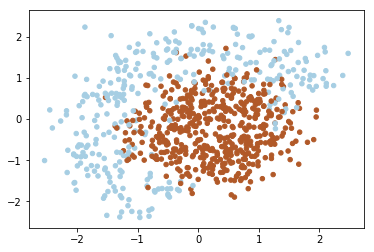
As you can notice the data above isn't linearly separable. Since that we should add features (or use non-linear model). Note that decision line between two classes have form of circle, since that we can add quadratic features to make the problem linearly separable. The idea under this displayed on image below:
#tests assertisinstance(dummy_expanded,np.ndarray), "please make sure you return numpy array" assert dummy_expanded.shape == dummy_expanded_ans.shape, "please make sure your shape is correct" assert np.allclose(dummy_expanded,dummy_expanded_ans,1e-3), "Something's out of order with features"
print("Seems legit!")
Seems legit!
Logistic regression
To classify objects we will obtain probability of object belongs to class '1'. To predict probability we will use output of linear model and logistic function:
\[ a(x; w) = \langle w, x \rangle \]\[ P( y=1 \; \big| \; x, \, w) = \dfrac{1}{1 + \exp(- \langle w, x \rangle)} = \sigma(\langle w, x \rangle)\]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
defprobability(X, w): """ Given input features and weights return predicted probabilities of y==1 given x, P(y=1|x), see description above Don't forget to use expand(X) function (where necessary) in this and subsequent functions. :param X: feature matrix X of shape [n_samples,6] (expanded) :param w: weight vector w of shape [6] for each of the expanded features :returns: an array of predicted probabilities in [0,1] interval. """ w = w.reshape((w.shape[0],1)) return1/(1 + np.exp(-np.dot(X,w)))
Loss for many samples: \[ L(X, \vec{y}, w) = {1 \over \ell} \sum_{i=1}^\ell l(x_i, y_i, w) \]
1 2 3 4 5 6 7 8 9
defcompute_loss(X, y, w): """ Given feature matrix X [n_samples,6], target vector [n_samples] of 1/0, and weight vector w [6], compute scalar loss function L using formula above. Keep in mind that our loss is averaged over all samples (rows) in X. """ y = y.reshape((y.shape[0],1)) return -np.mean(y*np.log(probability(X,w)) + (1-y)*np.log(1-probability(X,w))) # TODO:<your code here>
1 2
# use output of this cell to fill answer field ans_part2 = compute_loss(X_expanded, y, dummy_weights)
1 2
## GRADED PART, DO NOT CHANGE! grader.set_answer("HyTF6", ans_part2)
1 2
# you can make submission with answers so far to check yourself at this stage grader.submit(COURSERA_EMAIL, COURSERA_TOKEN)
Submitted to Coursera platform. See results on assignment page!
Since we train our model with gradient descent, we should compute gradients.
To be specific, we need a derivative of loss function over each weight [6 of them].
We won't be giving you the exact formula this time — instead, try figuring out a derivative with pen and paper.
As usual, we've made a small test for you, but if you need more, feel free to check your math against finite differences (estimate how \(L\) changes if you shift \(w\) by \(10^{-5}\) or so).
1 2 3 4 5 6 7 8 9
defcompute_grad(X, y, w): """ Given feature matrix X [n_samples,6], target vector [n_samples] of 1/0, and weight vector w [6], compute vector [6] of derivatives of L over each weights. Keep in mind that our loss is averaged over all samples (rows) in X. """ y = y.reshape((y.shape[0],1)) return np.mean(X*(probability(X,w) - y),axis = 0)
1 2
# use output of this cell to fill answer field ans_part3 = np.linalg.norm(compute_grad(X_expanded, y, dummy_weights))
1 2
## GRADED PART, DO NOT CHANGE! grader.set_answer("uNidL", ans_part3)
1 2
# you can make submission with answers so far to check yourself at this stage grader.submit(COURSERA_EMAIL, COURSERA_TOKEN)
Submitted to Coursera platform. See results on assignment page!
Here's an auxiliary function that visualizes the predictions:
In this section we'll use the functions you wrote to train our classifier using stochastic gradient descent.
You can try change hyperparameters like batch size, learning rate and so on to find the best one, but use our hyperparameters when fill answers.
Mini-batch SGD
Stochastic gradient descent just takes a random batch of \(m\) samples on each iteration, calculates a gradient of the loss on it and makes a step: \[ w_t = w_{t-1} - \eta \dfrac{1}{m} \sum_{j=1}^m \nabla_w l(x_{i_j}, y_{i_j}, w_t) \]
for i inrange(n_iter): ind = np.random.choice(X_expanded.shape[0], batch_size) loss[i] = compute_loss(X_expanded, y, w) if i % 10 == 0: visualize(X_expanded[ind, :], y[ind], w, loss)
# Keep in mind that compute_grad already does averaging over batch for you! # TODO:<your code here> random_index = np.random.randint(0,X_expanded.shape[0],batch_size) w = w - eta * compute_grad(X_expanded[random_index,:],y[random_index],w)
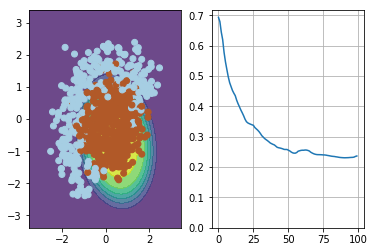
visualize(X, y, w, loss) plt.clf()
png
<matplotlib.figure.Figure at 0x7fdbbfafb908>
1 2
# use output of this cell to fill answer field ans_part4 = compute_loss(X_expanded, y, w)
1 2
## GRADED PART, DO NOT CHANGE! grader.set_answer("ToK7N", ans_part4)
1 2
# you can make submission with answers so far to check yourself at this stage grader.submit(COURSERA_EMAIL, COURSERA_TOKEN)
Submitted to Coursera platform. See results on assignment page!
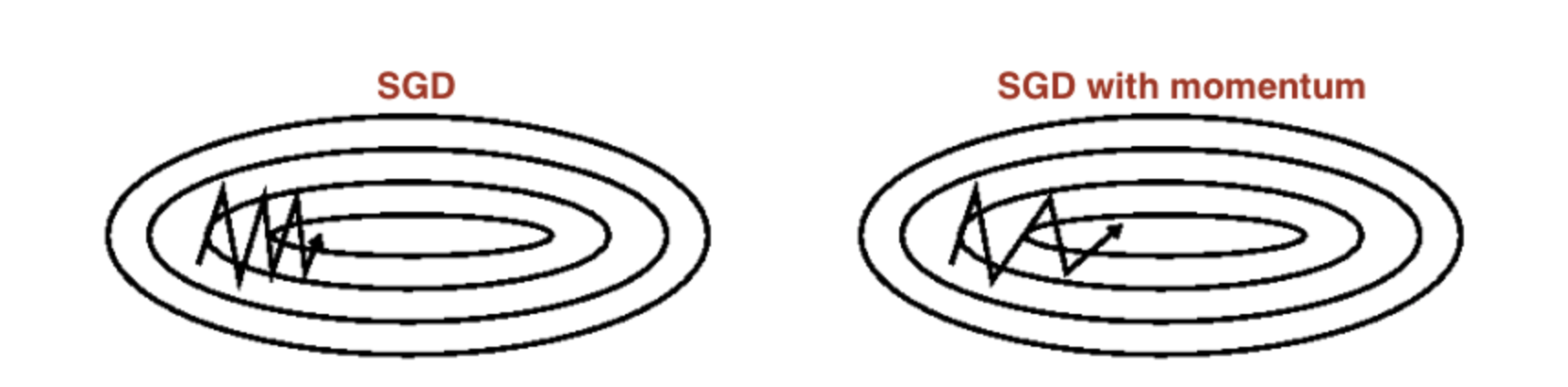
SGD with momentum
Momentum is a method that helps accelerate SGD in the relevant direction and dampens oscillations as can be seen in image below. It does this by adding a fraction \(\alpha\) of the update vector of the past time step to the current update vector.
for i inrange(n_iter): ind = np.random.choice(X_expanded.shape[0], batch_size) loss[i] = compute_loss(X_expanded, y, w) if i % 10 == 0: visualize(X_expanded[ind, :], y[ind], w, loss)
# TODO:<your code here> random_index = np.random.randint(0,X_expanded.shape[0],batch_size) nu = alpha*nu + eta * compute_grad(X_expanded[random_index,:],y[random_index],w) w = w - nu
visualize(X, y, w, loss) plt.clf()
png
<matplotlib.figure.Figure at 0x7fdbba216e10>
1 2 3
# use output of this cell to fill answer field
ans_part5 = compute_loss(X_expanded, y, w)
1 2
## GRADED PART, DO NOT CHANGE! grader.set_answer("GBdgZ", ans_part5)
1 2
# you can make submission with answers so far to check yourself at this stage grader.submit(COURSERA_EMAIL, COURSERA_TOKEN)
Submitted to Coursera platform. See results on assignment page!
RMSprop
Implement RMSPROP algorithm, which use squared gradients to adjust learning rate:
# please use np.random.seed(42), eta=0.1, alpha=0.9, n_iter=100 and batch_size=4 for deterministic results np.random.seed(42)
w = np.array([0, 0, 0, 0, 0, 1.])
eta = 0.1# learning rate alpha = 0.9# moving average of gradient norm squared g2 = None# we start with None so that you can update this value correctly on the first iteration eps = 1e-8 G = 0
n_iter = 100 batch_size = 4 loss = np.zeros(n_iter) plt.figure(figsize=(12,5)) for i inrange(n_iter): ind = np.random.choice(X_expanded.shape[0], batch_size) loss[i] = compute_loss(X_expanded, y, w) if i % 10 == 0: visualize(X_expanded[ind, :], y[ind], w, loss)
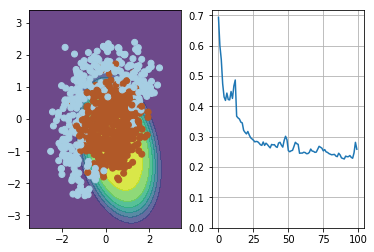
# TODO:<your code here> random_index = np.random.randint(0,X_expanded.shape[0],batch_size) g2 = np.square(compute_grad(X_expanded[random_index,:],y[random_index],w)) G = alpha*G + (1-alpha) * g2 w = w - eta/np.sqrt(G + eps) * g2 visualize(X, y, w, loss) plt.clf()
png
<matplotlib.figure.Figure at 0x7fdbba944f98>
1 2
# use output of this cell to fill answer field ans_part6 = compute_loss(X_expanded, y, w)
1 2
## GRADED PART, DO NOT CHANGE! grader.set_answer("dLdHG", ans_part6)
1
grader.submit(COURSERA_EMAIL, COURSERA_TOKEN)
Submitted to Coursera platform. See results on assignment page!