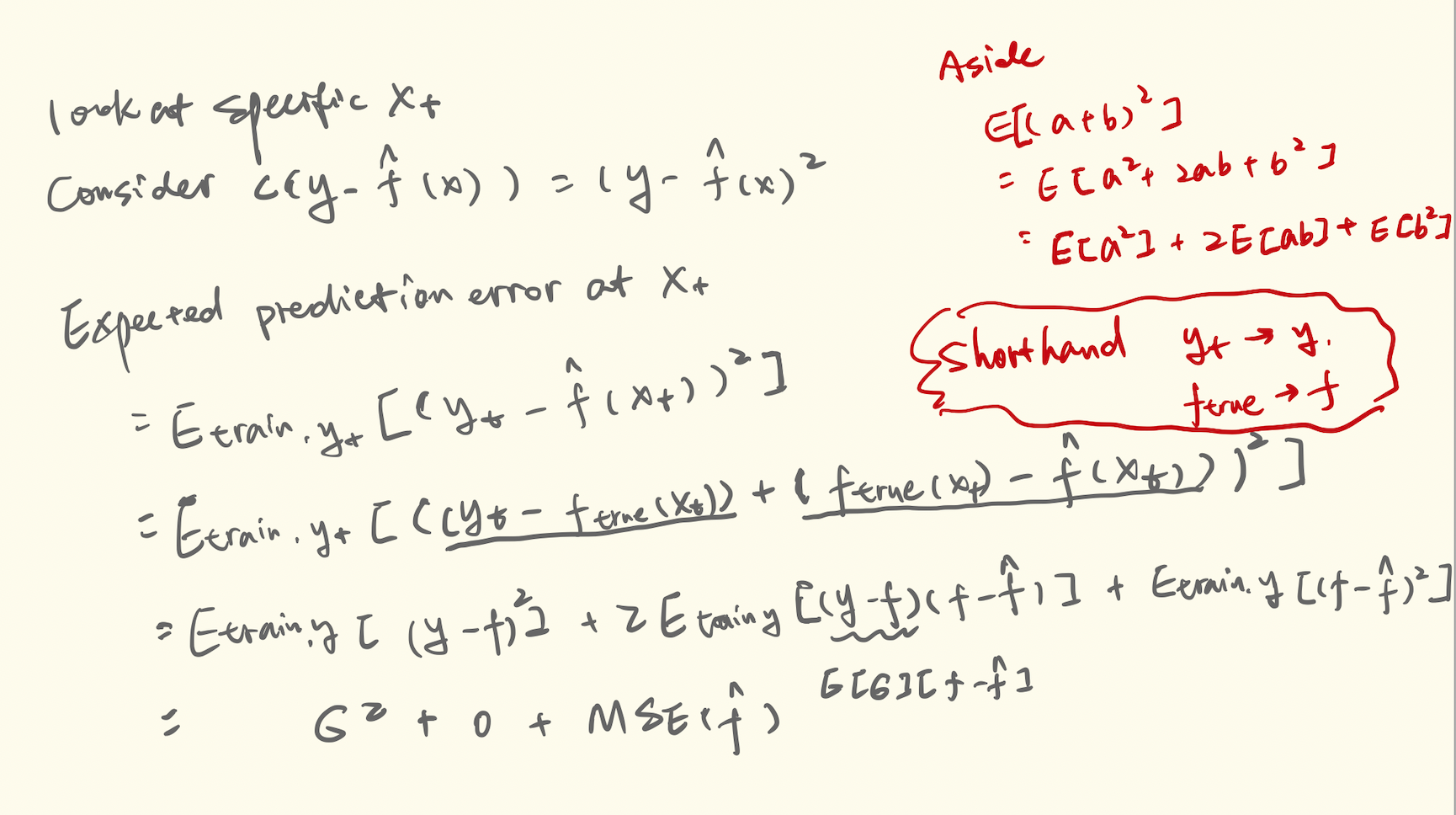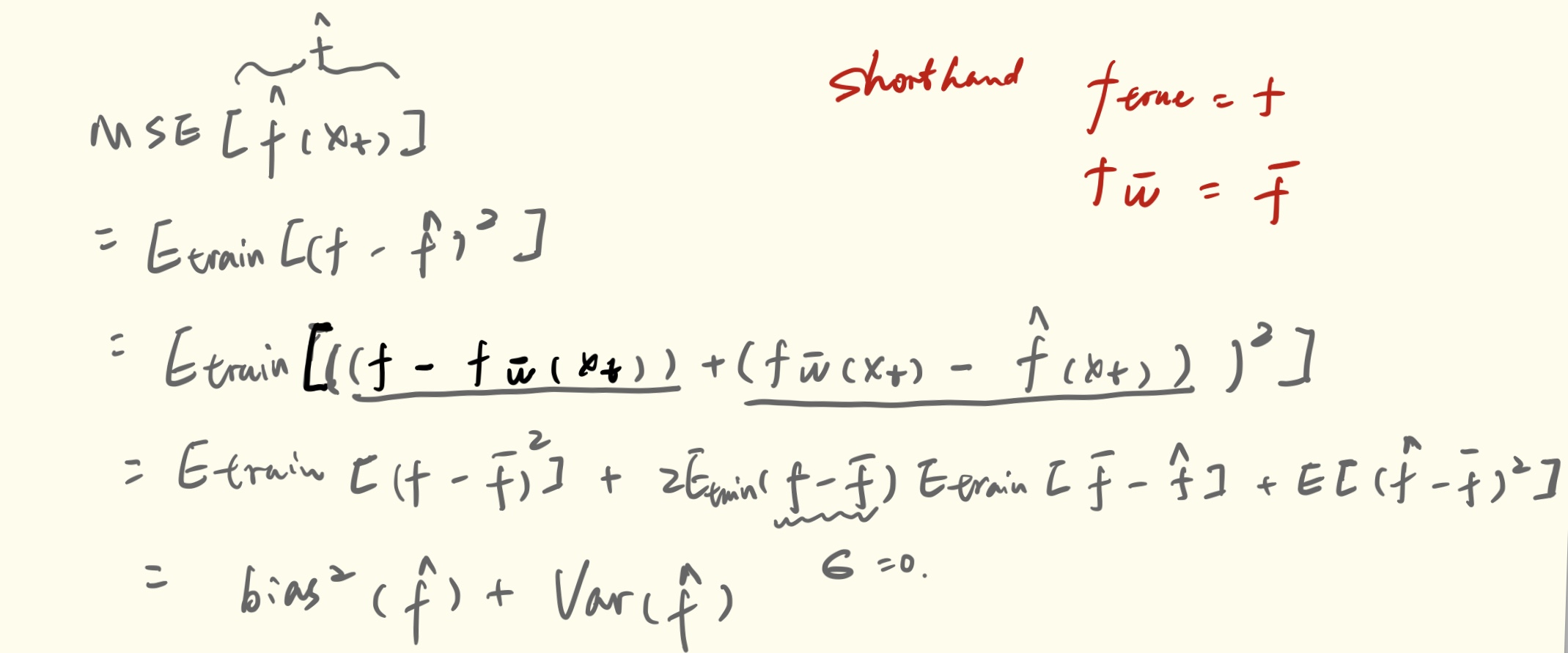3 sources of error
In forming predictions, there are 3 sources of error:
- Noise
- Bias
- Variance
Noise contribution
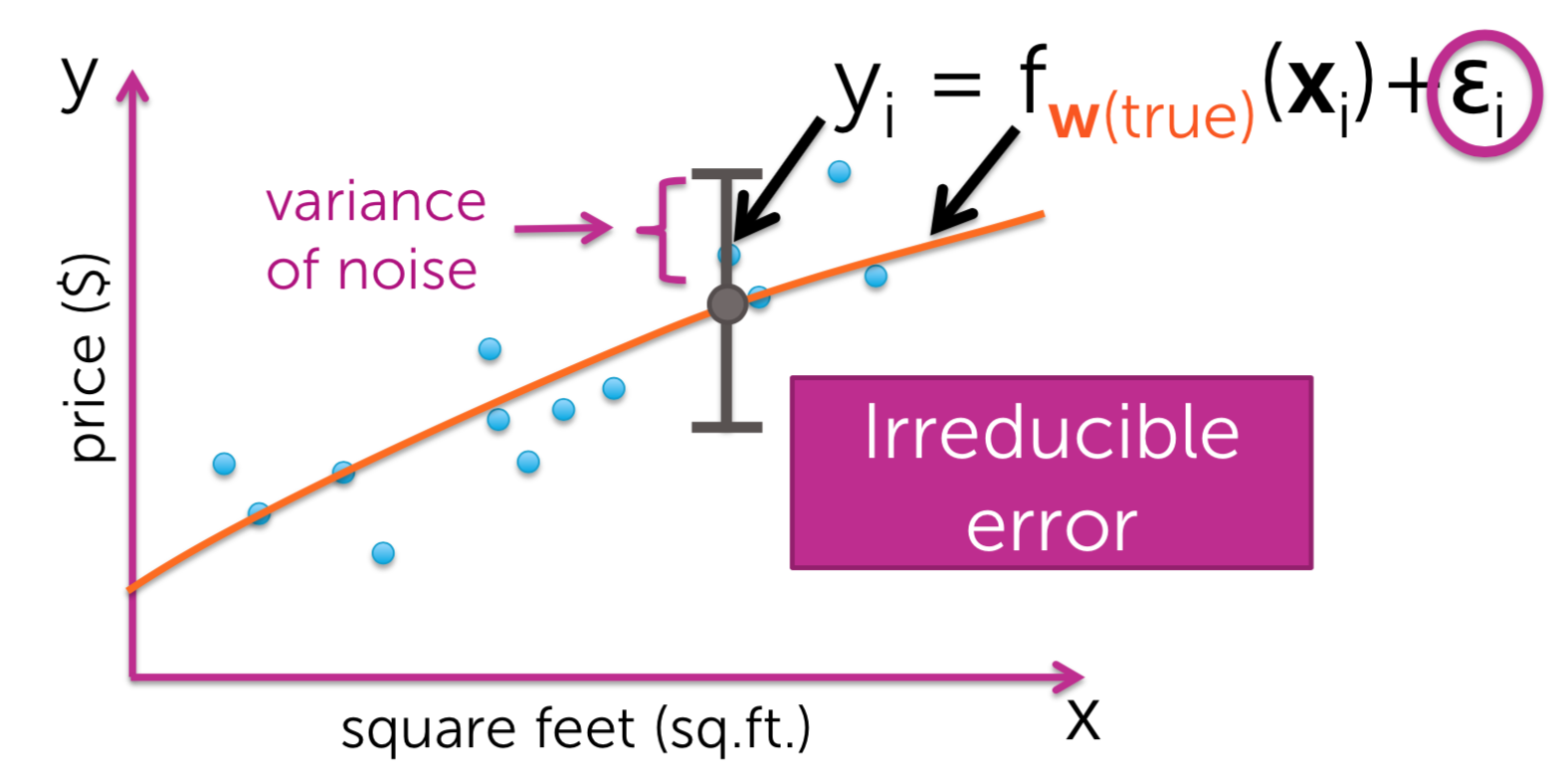
Data inherently noisy
The world works is that there's some true relationship between X and Y. Or generically, between x and y. And we're representing that arbitrary relationship defined by the world, by \(f_{w}\) true. Which is the notation we're using for that functional relationship. But of course that's not a perfect description between x and y. There are lot of other contributing factors have the impact on y. Lots and lots of other things that we can't ever perfectly capture with just some function between x and y, and so that is the noise that's inherent in this process represented by this epsilon term.
Bias contribution
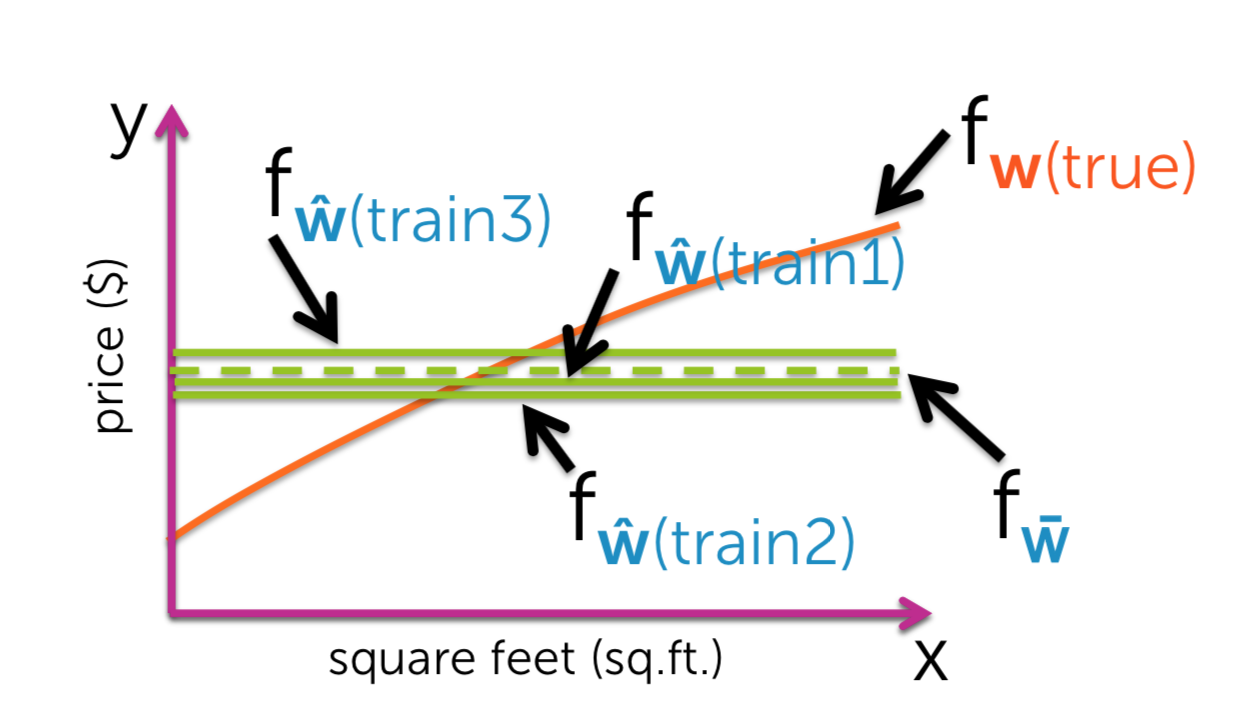
\[Bias(x) = f_{w}(X) - f_{\hat{w}}(X)\]
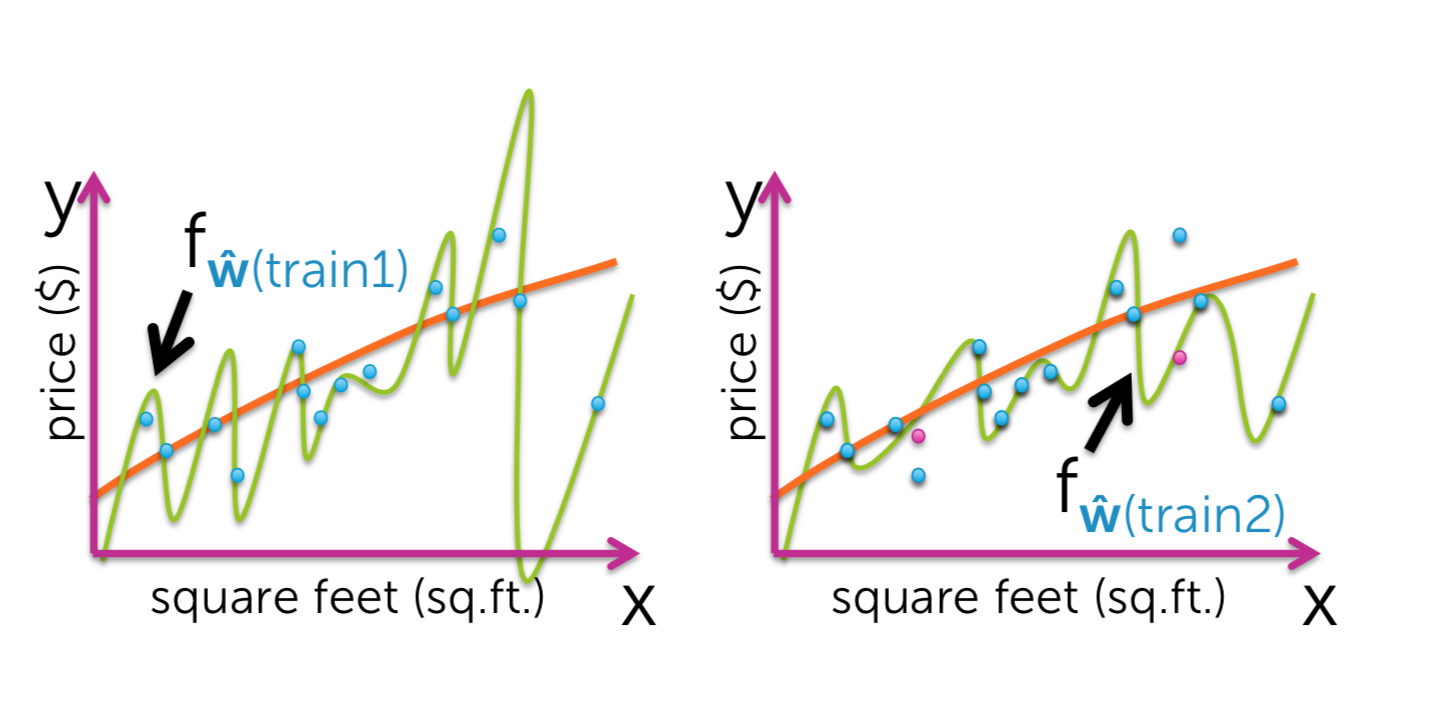
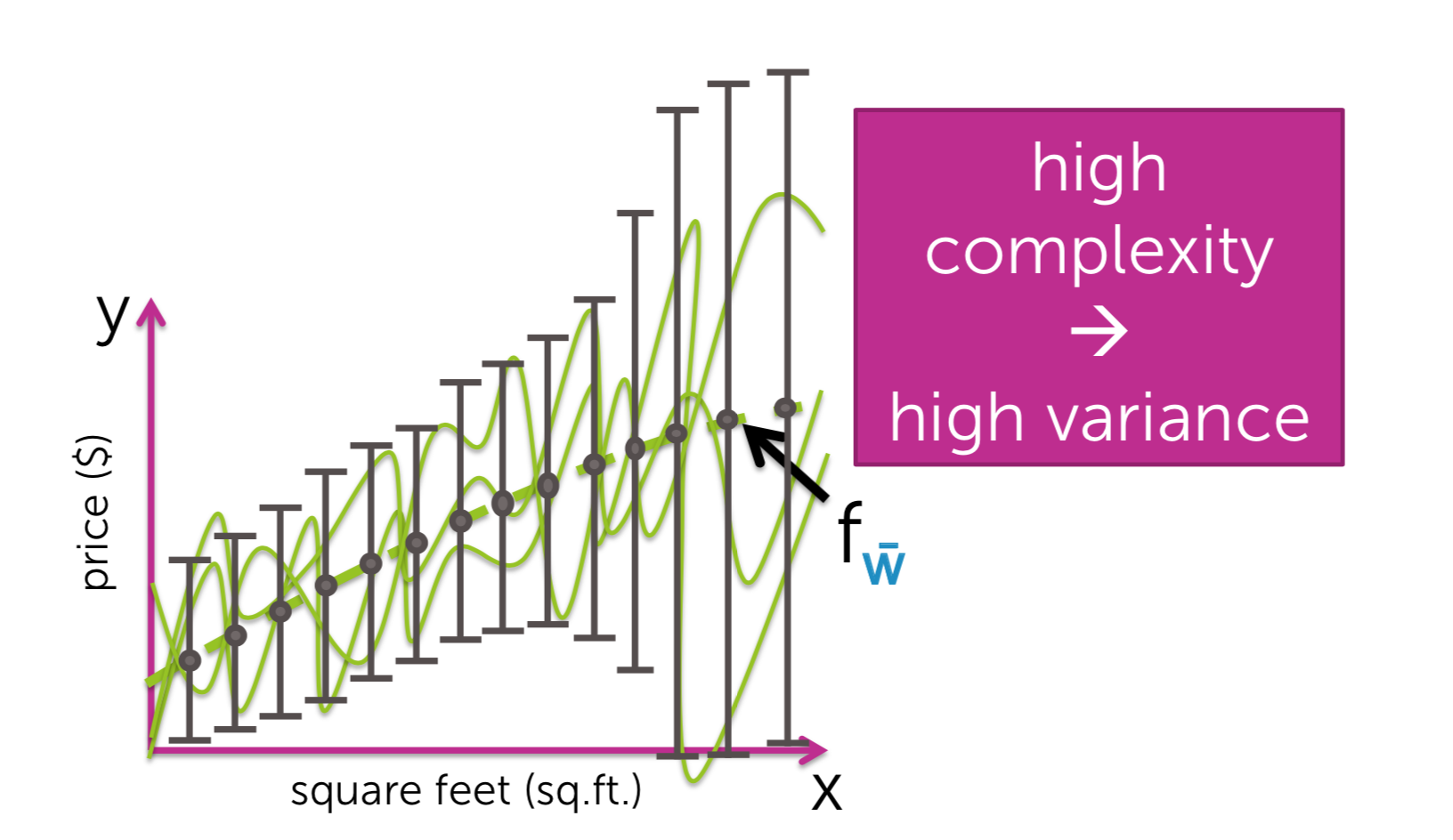
For one data set of size N, we get this fit. But there are other datasets. For the fits associated with those data sets. there's a continuum of possible fits we might have gotten. And for all those possible fits, here this dashed green line represents our average fit, averaged over all those fits weighted by how likely they were to have appeared. What bias is it's the difference between this average fit and the true function.
Variance contribution
What variance is how different can my specific fits to a given data set be from one another, as I'm looking at different possible data sets? To summarize what this variance is saying is, how much can the fits vary?
Average prediction error at x_{t}
\[\sigma^{2} + [bias(f_{\hat{w}}(X_{t}))]^{2} + var(f_{\hat{w}}(X_{t})) \]

prove