Three problem need to solve when realize lifelong learnig
- Knowledge Retention
- Knowledge Transfer
- Model Expansion
Knowledge Retention
When a network learn a new task. It has the inclination to forget the skills it has learned. The phenomenon that the model will forget the previous skills is called Catastrophic Forgetting.
The reason for resulting the catastrophic forgetting is not the model's size which has no enough capacity to learn the new skills. To prove this we can make the model to learn a multi-task problem and get a good results.

Idea
The ideas to solve knowledge retention
Elastic Weight Consolidation
\[L^{\prime}(\theta) = L(\theta) + \lambda \sum_{i} b_i(\theta_i - \theta_i^{b})^2\]
- \(L^{\prime}(\theta)\) : the loss to be optimized
- \(L(\theta)\) : the loss of current task
- \(\theta_i\) : the parameters to be learning
- \(\theta_i^{b}\) : the parameters leaned from previous tasks
- \(b_i\) how important the parameter is
the idea of EWC is: learning the new parameters which are not far from the previous parameters
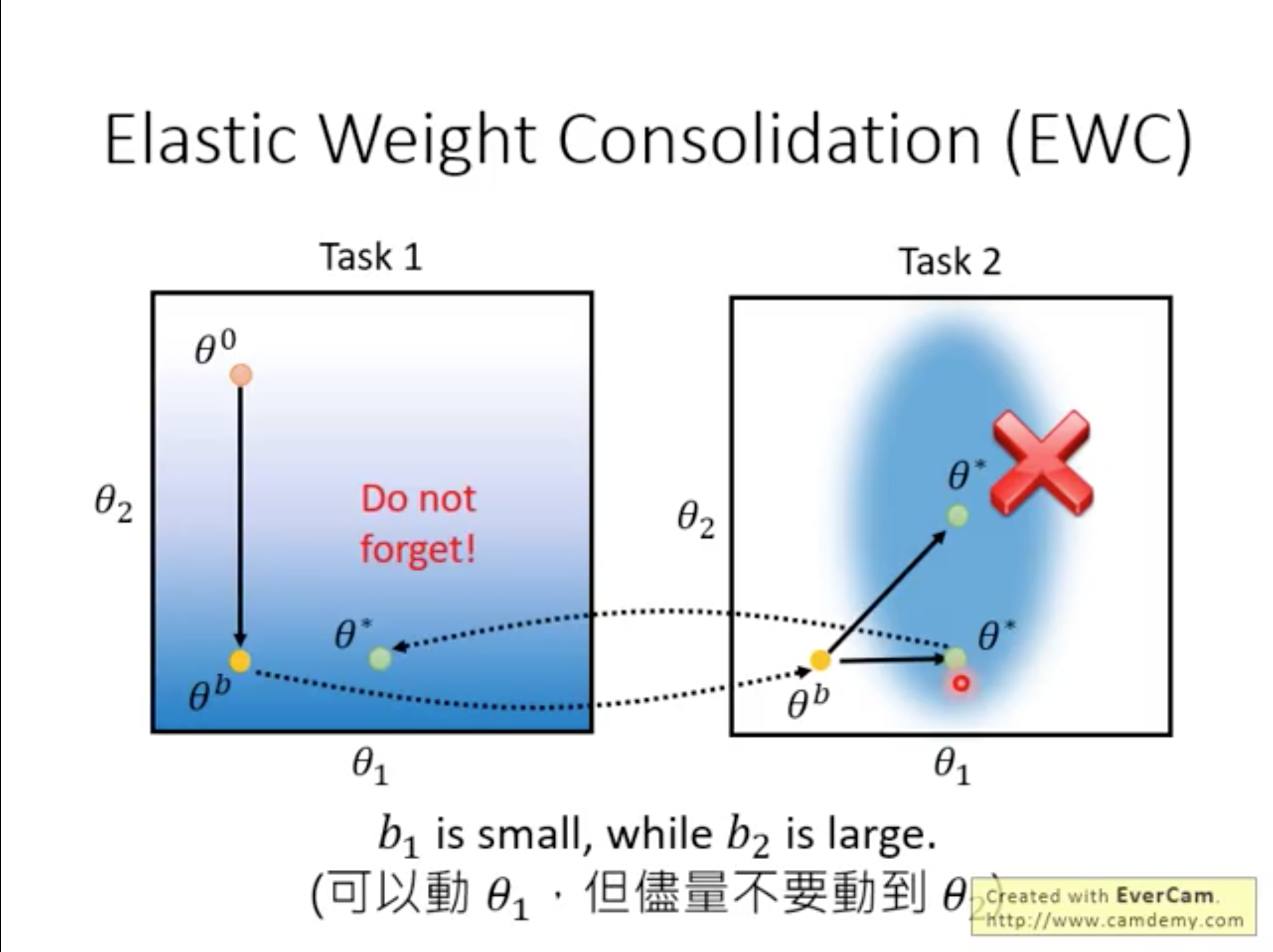
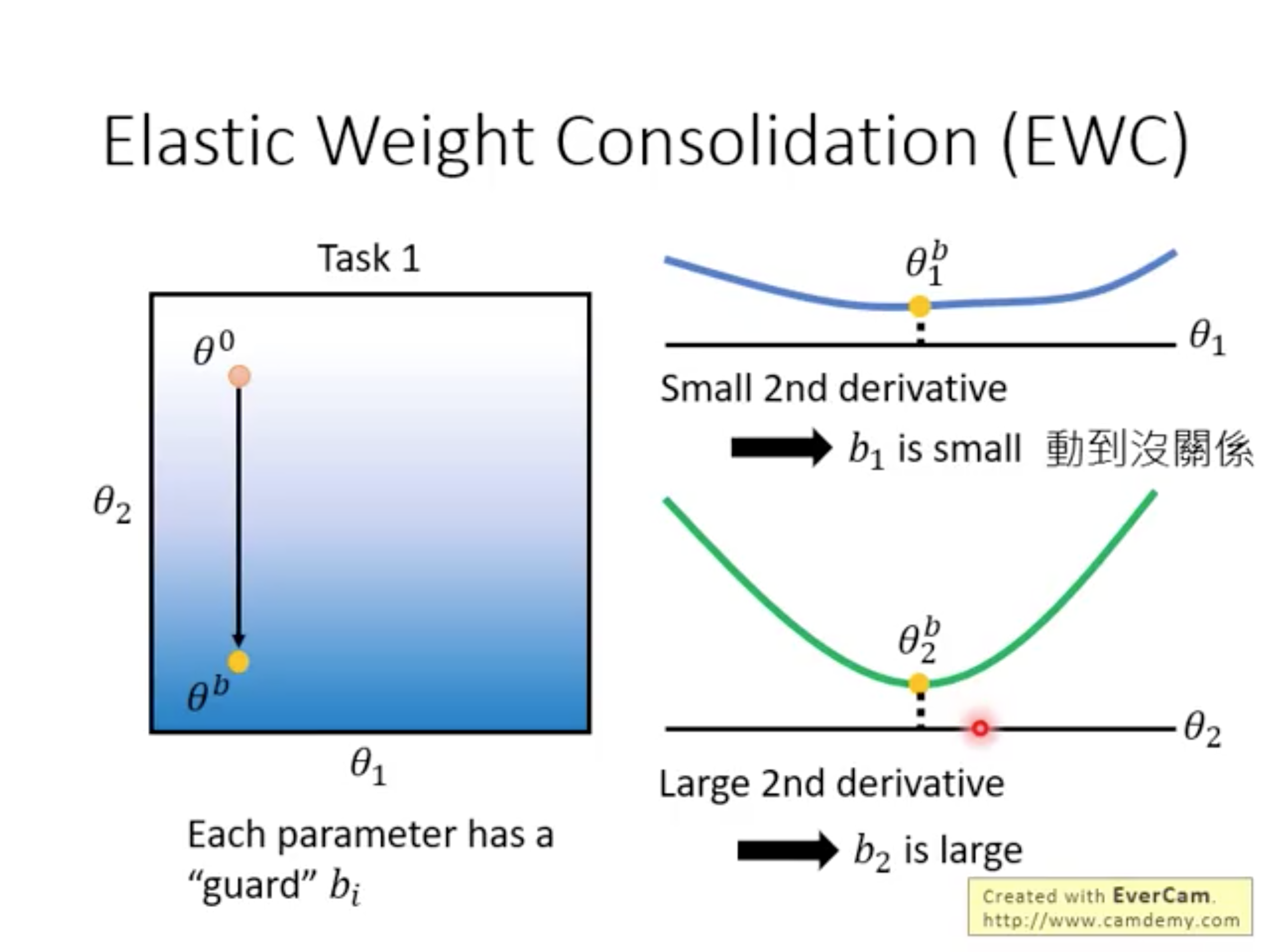
How to set \(b_i\) ?
- small 2nd derivative -> set \(b_i\) to small or large
- large 2nd derivative -> set \(b_i\) to small
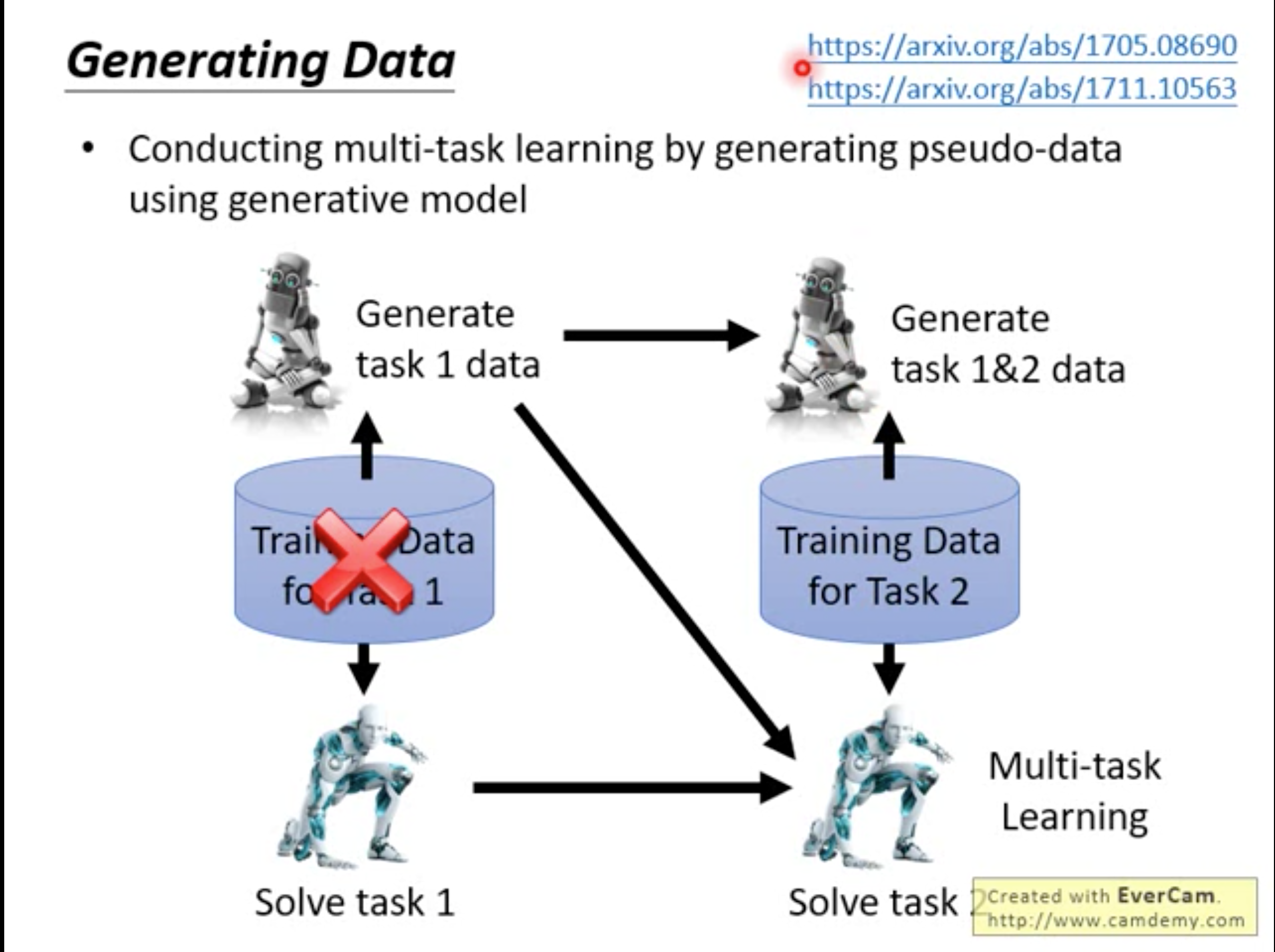
Generating Data
Conducting multi-task learning by generating pseudo-data using generative model.
We know the multi-task learning is a good way to solve life long task(sometimes it is the upper bound). If a new task come, we can regard it as a multi-task problem combined with previous tasks and build a model to solve it. But the premise of dong this is we have the data of previous tasks. In reality, we can not store all the dataset of previous tasks. Therefore, We can use generative model to generate previous dataset.
Knowledge Transfer
The difference of knowledge transfer between lifelong learning with transfer learning is that transfer learning is just concentrate on new task while the lifelong learning shuild consider the catastrophic forgetting
Gredient Episodic Memory
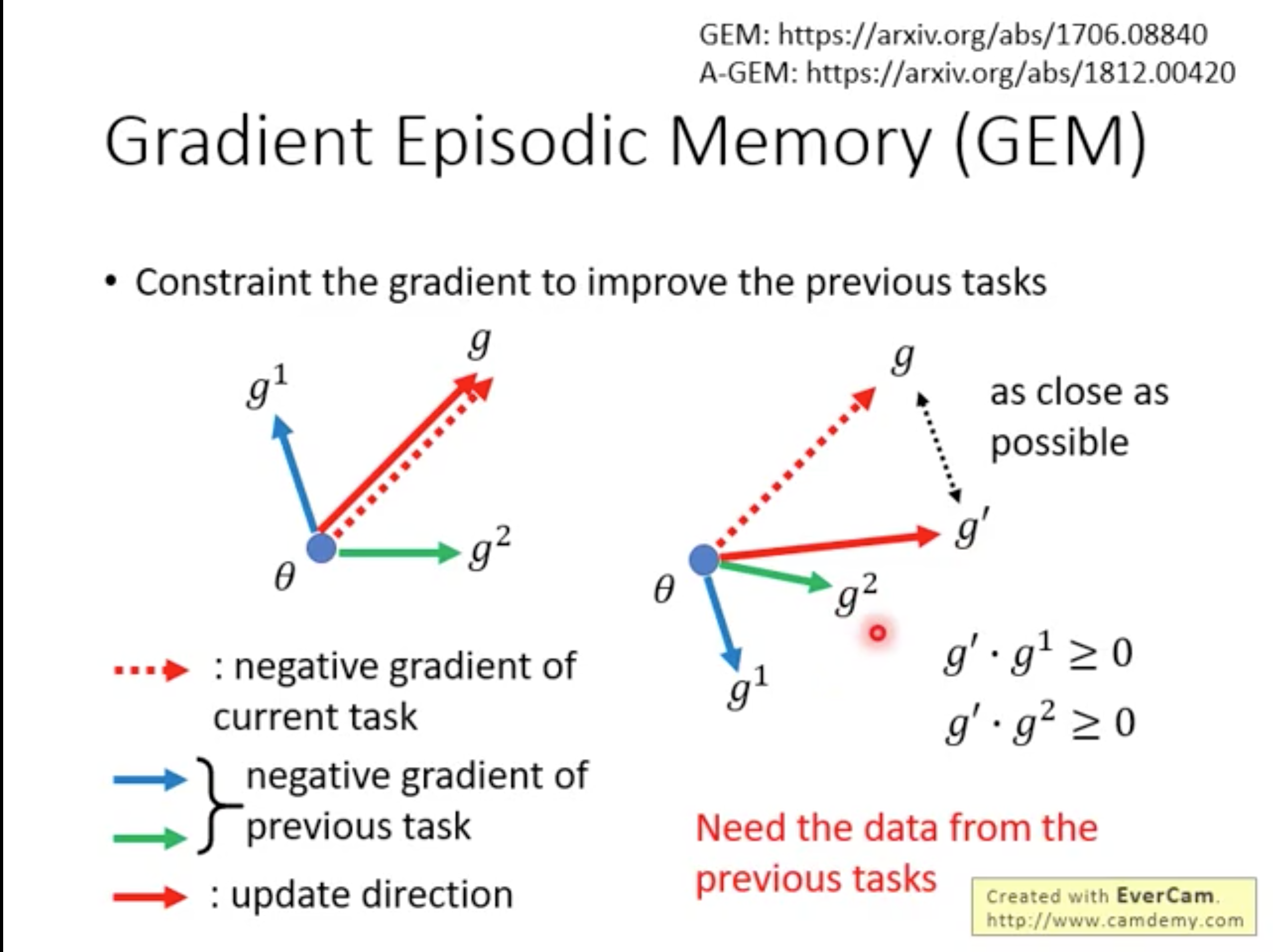
The idea of GEM is: When we update the parameters by gredient descent we can find a direction which can benifits the previous tasks and new tasks to update. The disadvantages of GEM is we need store a little bit of data of previous tasks.
Model Expansion
Progressive Neural Networks
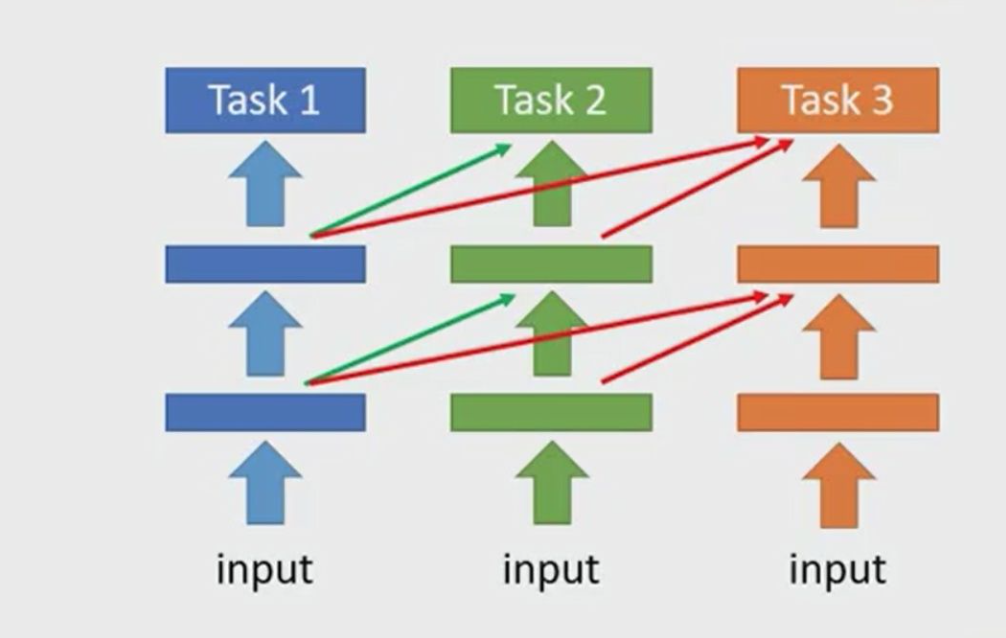
An example of model expansion is the Progressive Neural Networks proposed in 2016. We fix the parameters after learning some tasks, and then train the new task. We build a new model and use the output of previous task as the input of new task. However, there is a disadvantage that you can not train too many new tasks because it will cause a lot of load.
Expert Gate
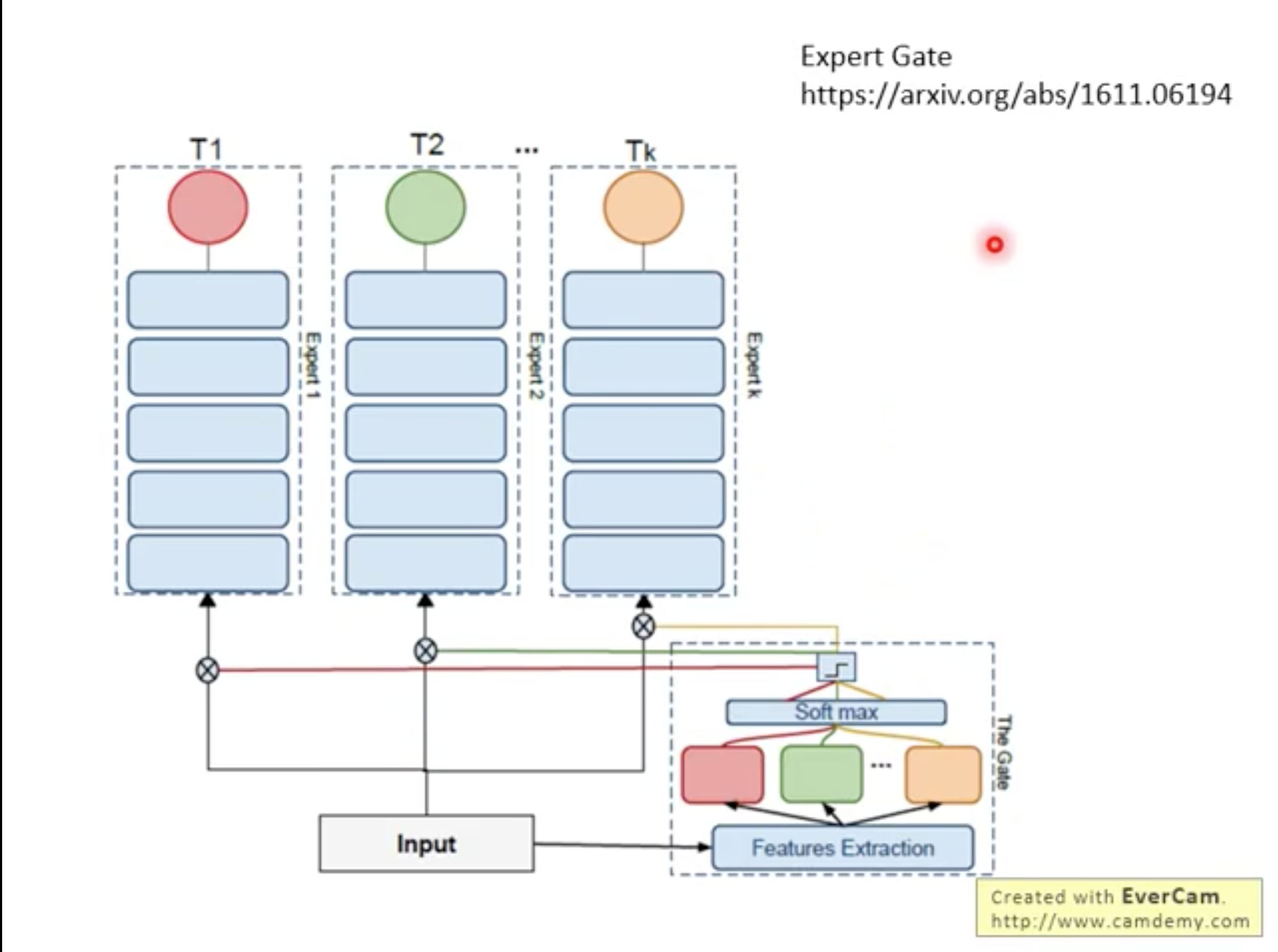
Exper Gate's method: We still have one model for each task. For example, we have three tasks, and the fourth task is similar to the first one (we use Gate to determine which new task is similar to the old one), then we will use the model of the first task as the fourth Initialization of each task model, this has formed a certain migration effect. However, this method is still a task corresponding to a model, which still causes a lot of load on storage.
Tasknomy
The order of learning tasks is just like the order of our textbooks, which has a great impact on the final results. (This is a optimal order for the learning tasks).