import os os.environ["CUDA_VISIBLE_DEVICES"] = "0"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import numpy as np from scipy.optimize import fmin_l_bfgs_b
from keras import backend as K from keras.preprocessing.image import load_img, save_img, img_to_array from keras.applications import vgg19 from keras.optimizers import Adam
from keras.preprocessing import image from keras.applications.vgg19 import preprocess_input from keras.models import Model
defdeprocess_image(x): x = x.reshape((img_nrows, img_ncols, 3)) # Remove zero-center by mean pixel x[:, :, 0] += 103.939 x[:, :, 1] += 116.779 x[:, :, 2] += 123.68 # 'BGR'->'RGB' x = x[:, :, ::-1] x = np.clip(x, 0, 255).astype('uint8') return x
defextract_features(x, content_layers, style_layers): contents = [] styles = [] for layer in model.layers: x = layer(x) if layer.name in content_layers: contents.append(x) if layer.name in style_layers: styles.append(x) return contents,styles
defget_contents(image): """ extract feature from image """ x = image.img_to_array(content_image) x = np.expand_dims(x, axis=0) x = preprocess_input(x) y = extract_features(x, content_layers, style_layers) return x,y
WARNING: Logging before flag parsing goes to stderr.
W0814 07:28:44.852089 140562742982464 deprecation_wrapper.py:119] From /home/rczhang/miniconda3/envs/ali_comp/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:517: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.
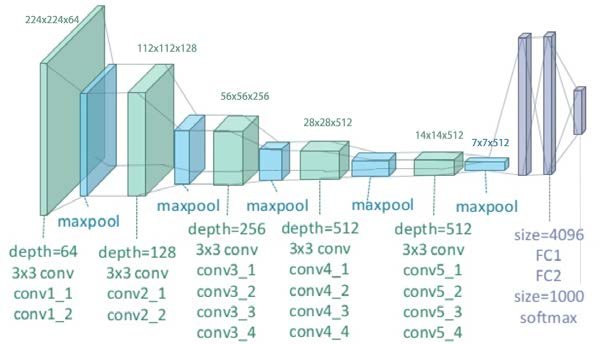
content_layers = "block5_conv4" style_layers = ["block1_conv1","block2_conv1","block3_conv1","block4_conv1","block5_conv1"] outputs_dict = dict([(layer.name, layer.output) for layer in model.layers])
Loss
Content loss
Style loss
对于样式,我们可以简单将它看成是像素点在每个通道的统计分布。例如要匹配两张图像的样式, 我们可以匹配这两张图像在 RGB 这三个通道上的直方图。更一般的,假设卷积层的输出格式是c × h × w,既(通道,高,宽)。那么我们可以把它变形成 c × hw 的二维数组,并将它看成是一 个维度为 c 的随机变量采样到的 hw 个点。所谓的样式匹配就是使得两个 c 维随机变量统计分布 一致。匹配统计分布常用的做法是冲量匹配,就是说使得他们有一样的均值,协方差,和其他高维的冲量。为了计算简单起⻅,我们只匹配二阶信息,即协方差。
defgram_matrix(x): assert K.ndim(x) == 3 if K.image_data_format() == 'channels_first': features = K.batch_flatten(x) else: features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1))) gram = K.dot(features, K.transpose(features)) return gram
# the "style loss" is designed to maintain # the style of the reference image in the generated image. # It is based on the gram matrices (which capture style) of # feature maps from the style reference image # and from the generated image
for layer_name in style_layers: layer_features = outputs_dict[layer_name] style_reference_features = layer_features[1, :, :, :] combination_features = layer_features[2, :, :, :] sl = style_loss(style_reference_features, combination_features) loss += (style_weight / len(style_layers)) * sl loss += total_variation_weight * total_variation_loss(combination_image) grads = K.gradients(loss, combination_image)
W0814 07:28:58.561622 140562742982464 variables.py:2429] Variable += will be deprecated. Use variable.assign_add if you want assignment to the variable value or 'x = x + y' if you want a new python Tensor object.
W0814 07:29:00.537572 140562742982464 deprecation.py:323] From /home/rczhang/miniconda3/envs/ali_comp/lib/python3.6/site-packages/tensorflow/python/ops/math_grad.py:1205: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
iterations = 100 result_prefix = "chenzai" x = preprocess_image(base_image_path)
for i inrange(iterations): print('Start of iteration', i) x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x.flatten(), fprime=evaluator.grads, maxfun=20) print('Current loss value:', min_val) # save current generated image img = deprocess_image(x.copy()) fname = result_prefix + '_at_iteration_%d.png' % i save_img(fname, img) print('Image saved as', fname)
Start of iteration 0
Current loss value: 1674930200000.0
Image saved as chenzai_at_iteration_0.png
Start of iteration 1
Current loss value: 717802100000.0
Image saved as chenzai_at_iteration_1.png
Start of iteration 2
Current loss value: 454865100000.0
Image saved as chenzai_at_iteration_2.png
Start of iteration 3
Current loss value: 328861320000.0
Image saved as chenzai_at_iteration_3.png
Start of iteration 4
Current loss value: 268055990000.0
Image saved as chenzai_at_iteration_4.png
Start of iteration 5
Current loss value: 222694330000.0
Image saved as chenzai_at_iteration_5.png
Start of iteration 6
Current loss value: 191597500000.0
Image saved as chenzai_at_iteration_6.png
Start of iteration 7
Current loss value: 170507350000.0
Image saved as chenzai_at_iteration_7.png
Start of iteration 8
Current loss value: 151088100000.0
Image saved as chenzai_at_iteration_8.png
Start of iteration 9
Current loss value: 138113840000.0
Image saved as chenzai_at_iteration_9.png
Start of iteration 10
Current loss value: 129697645000.0
Image saved as chenzai_at_iteration_10.png
Start of iteration 11
Current loss value: 122296410000.0
Image saved as chenzai_at_iteration_11.png
Start of iteration 12
Current loss value: 113507475000.0
Image saved as chenzai_at_iteration_12.png
Start of iteration 13
Current loss value: 107962425000.0
Image saved as chenzai_at_iteration_13.png
Start of iteration 14
Current loss value: 97767780000.0
Image saved as chenzai_at_iteration_14.png
Start of iteration 15
Current loss value: 91393800000.0
Image saved as chenzai_at_iteration_15.png
Start of iteration 16
Current loss value: 87411384000.0
Image saved as chenzai_at_iteration_16.png
Start of iteration 17
Current loss value: 83964305000.0
Image saved as chenzai_at_iteration_17.png
Start of iteration 18
Current loss value: 80351320000.0
Image saved as chenzai_at_iteration_18.png
Start of iteration 19