Hashing
We want to define a keyspace, a (mathematical) description of the keys for a set of data, using a function to map the keyspace into a small set of integers.
A Hash Table consists of three things:
- Hash Function
- An array
- Collision
Hash Function
Our hash function consists of two parts: - A hash: transfrom input to an integer(index) - A compression: make the hash function within the bounds of the arrays(%N).
Characteristics of a good hash function: - Computation Time - Deterministic - Satisfythe SUHA(simple unifrom hashing assumption)
std::map
std::map
- std::operator[]
- ::insert ::erase
- ::lower_bound(key) -> Iterator to first element ≤ key
- ::upper_bound(key) -> Iterator to first element > key
- std::unordered_map
- std::operator[]
- std::insert
- std::erase
- std::load_factor()
- std::max_load_factor(ml) -> Sets the max load factor
Disjoint Sets
https://zhangruochi.com/Union-Find/2019/11/19/
- Maintain a collection S = {\(s_0\), \(s_1\), , \(s_k\)}.
- Each set has a representative member.
Disjoint Sets ADT
1 | void makeSet(const T & t); |
In an Disjoint Sets implemented with smart unions and path compression on find
1 | int DisjointSets::find(int i) { |
1 | void DisjointSets::unionBySize(int root1, int root2) { |
1 |
|
Graph
Graph ADT
Data: - Vertices - Edges - Some data structure maintaining the structure between vertices and edges.
Functions: - insertVertex(K key); - insertEdge(Vertex v1, Vertex v2, K key); - removeVertex(Vertex v); - removeEdge(Vertex v1, Vertex v2); - incidentEdges(Vertex v); - areAdjacent(Vertex v1, Vertex v2); - origin(Edge e); - destination(Edge e);
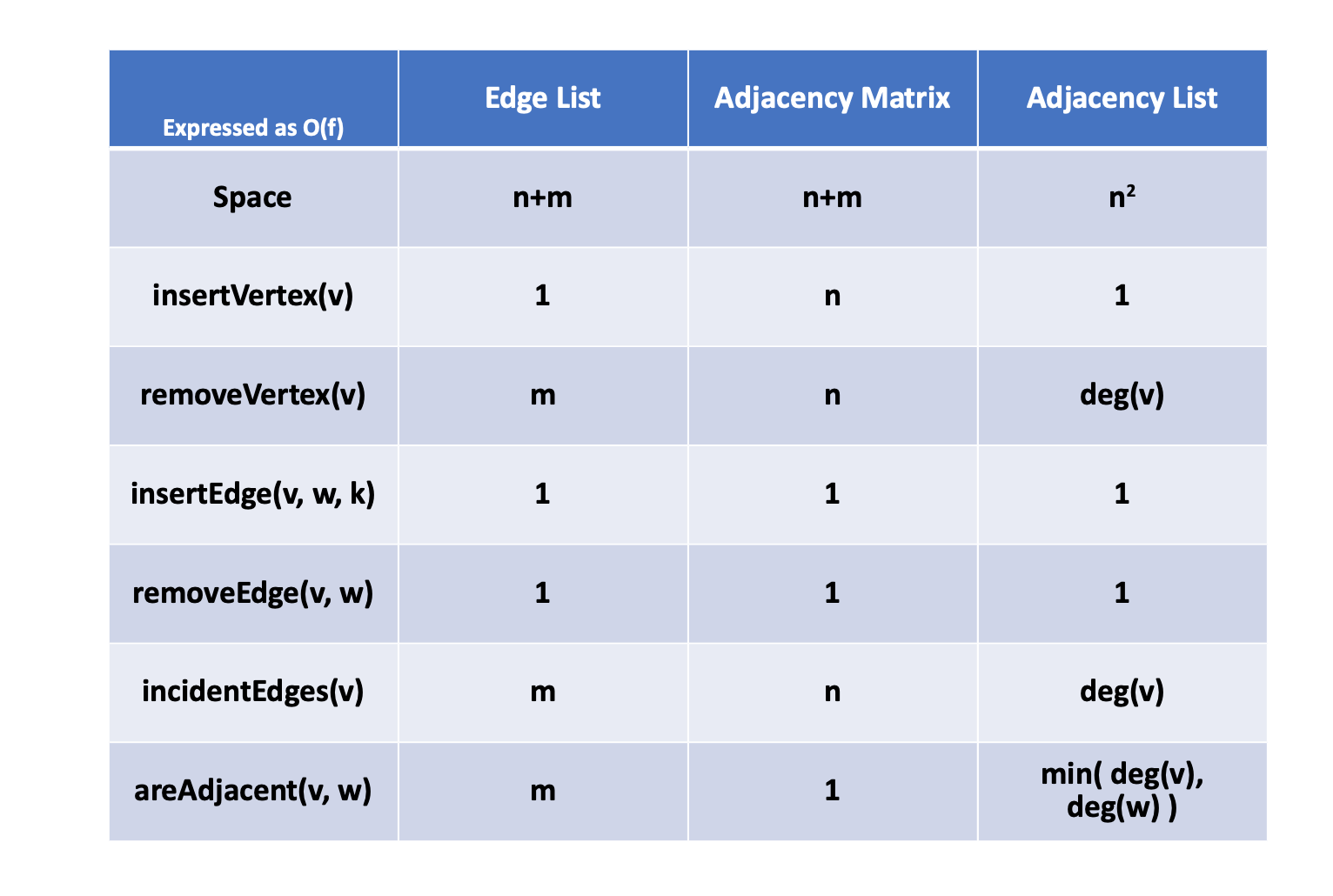
Graph Implementation: Edge List
- insertVertex: O(1)
- removeVertex: O(1)
- areAdjancet: O(m)
- incidentEdges: O(m)
Graph Implementation: Adjacnecy Matrix
- insertVertex: O(n)
- removeVertex: O(n)
- areAdjancet: O(1)
- incidentEdges: O(n)
Graph Implementation: Adjacnecy List
- insertVertex: O(1)
- removeVertex: O(degree v)
- areAdjancet: min(dgree(v1), degree(v2))
- incidentEdges: O(degree v)