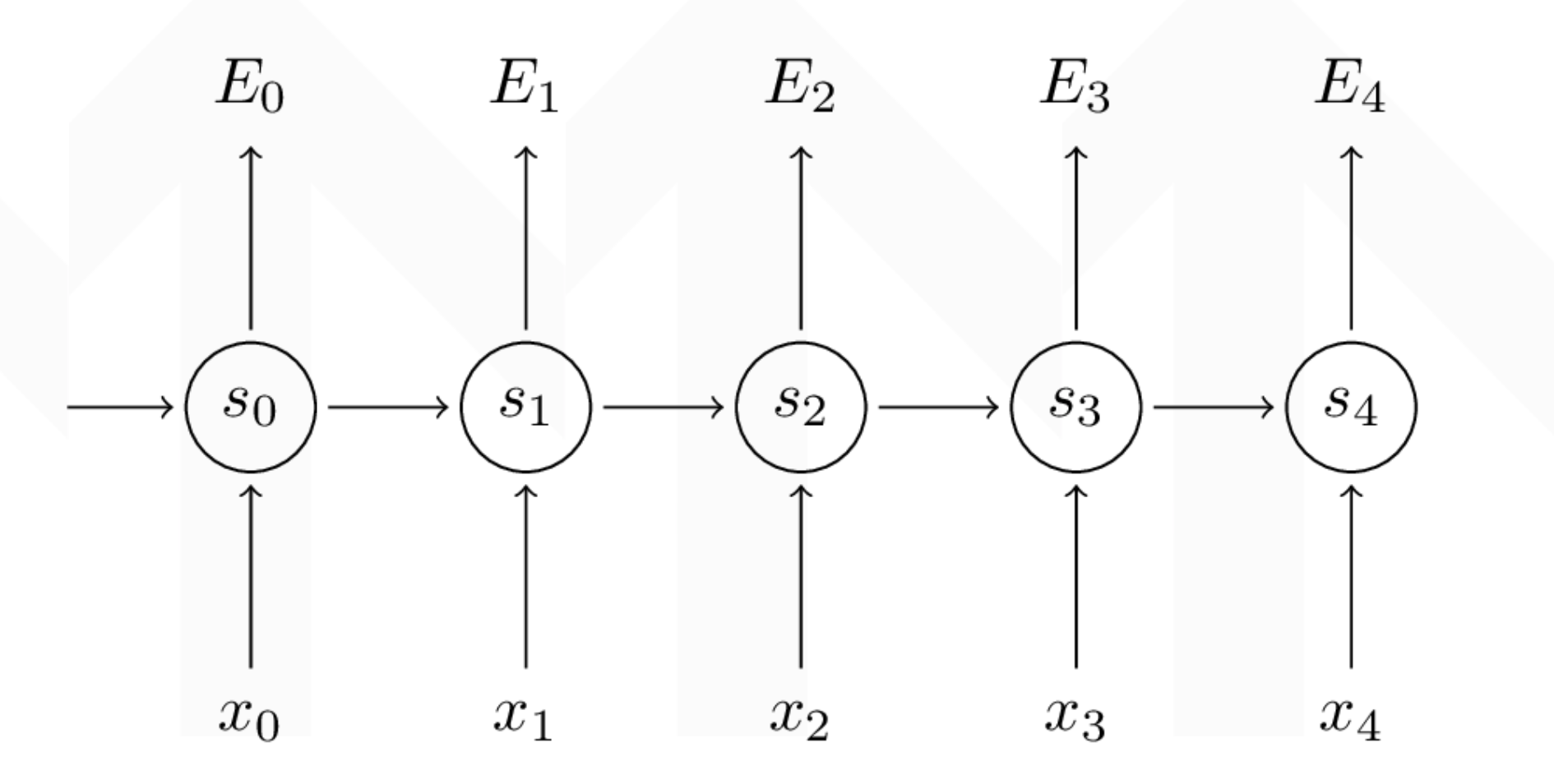
The formula of recurrent neural network (rnn)
\[s_{t} = tanh(U x_{t} + W s_{t-1})\] \[\hat{y_{t}} = softmax(V s_{t})\]
The loss is:
\[E_{t}(y_{t},\hat{y_{t}}) = -y_{t}log(\hat{y_{t}})\] \[E_{t}(y,\hat{y}) = \sum_{t}E_{t}(y_{t},\hat{y_{t}})=-\sum_{t}y_{t}log(\hat{y_{t}})\]
Our purpose is to calculate the gradient of U,V,W and use it to update themself. Just like we add up the loss, we should add up the gradient of all the time steps.
\[\frac{\partial E}{\partial W} = \sum_{t}\frac{\partial E_{t}}{\partial W}\]
Take \(E_3\) for example:
\[\frac{\partial E_{3}}{\partial V} = \frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial V} =\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial z_{3}} \frac{\partial z_{3}}{\partial V}=(\hat{y_{3}} - y_{3}) \otimes s_{3}\]
What important here is \(\frac{\partial E_{3}}{\partial V}\) just depend on current time step
But \(\frac{\partial E_{3}}{\partial W}\) is different. And u is same as w.
\[\frac{\partial E_{3}}{\partial W}=\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} \frac{\partial s_{3}}{\partial W}\]
\(s_{3} = tanh(U x_{t} + W s_{2})\) depend on \(s_{2}\) and \(s_2\) depend on \(W\) and \(s_1\). if we calculate the gradient of \(w\), we can not regard it as contant value.
We should add up gradient from all the time steps。In other words,the output of all the time steps depend on W.
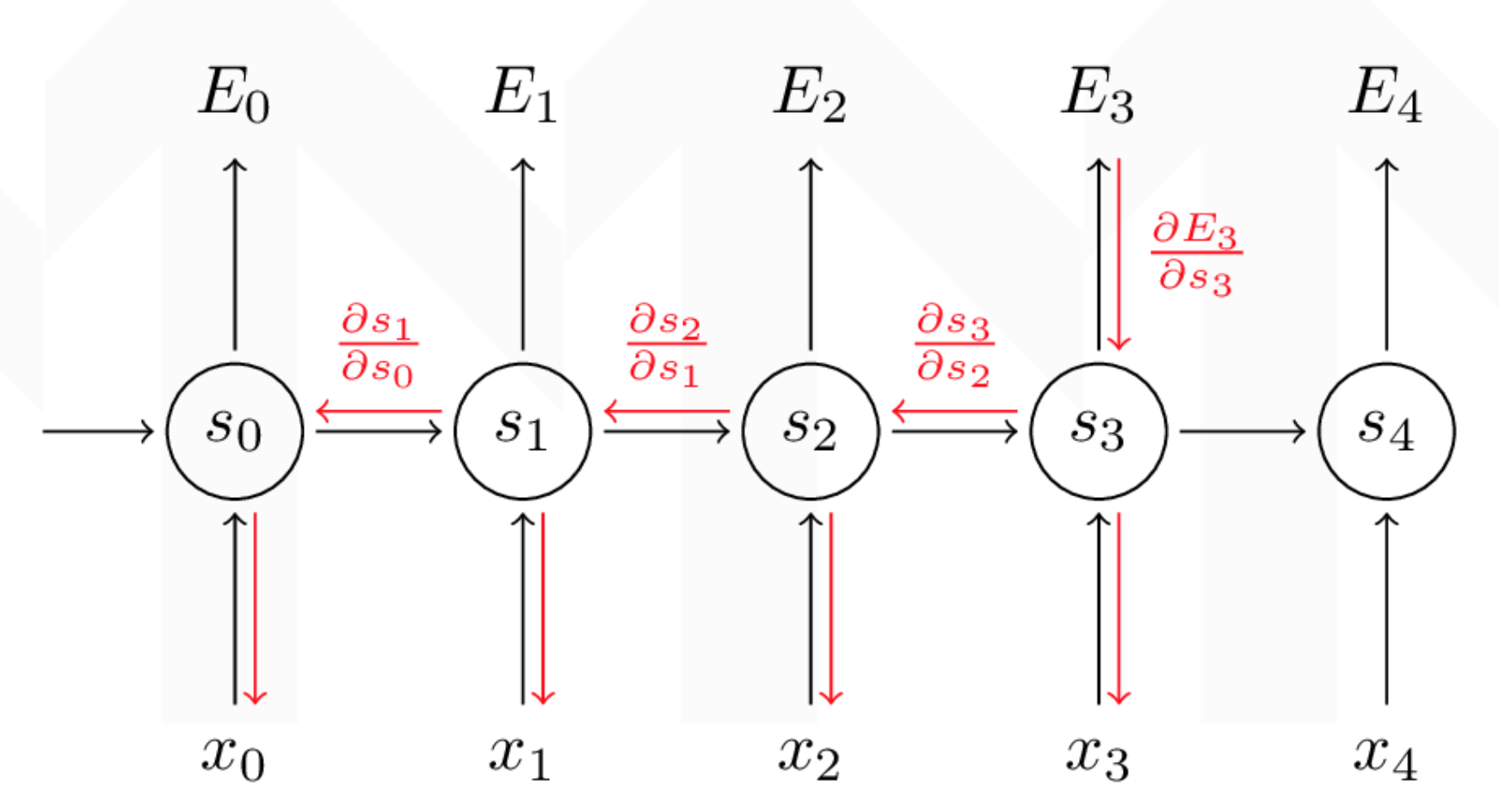
Why gradient vanish
we can see the gradient formula:
\[\frac{\partial E_{3}}{\partial W}= \sum_{k=0}^{3}\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{k}} \frac{\partial s_{k}}{\partial W} = \frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{w}} + \frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{2}} \frac{\partial s_{2}}{\partial s_{w}} + \frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} \frac{\partial s_{3}}{\partial s_{2}} \frac{\partial s_{2}}{\partial s_{1}} \frac{\partial s_{1}}{\partial s_{w}}\]
\(\frac{\partial s_{3}}{\partial s_{k}}\)is a chian rule. for example: \(\frac{\partial s_{3}}{\partial s_{1}} = \frac{\partial s_{3}}{\partial s_{2}} \frac{\partial s_{2}}{\partial s_{1}}\). if we reformula it:
\[\frac{\partial E_{3}}{\partial W}=\sum_{k=0}^{3}\frac{\partial E_{3}}{\partial \hat{y_{3}}} \frac{\partial \hat{y_{3}}}{\partial s_{3}} (\prod_{j = k+1}^{3} \frac{\partial s_{j}}{\partial s_{j-1}}) \frac{\partial s_{k}}{\partial W}\]