Feature Preprocessing
Numeric feature
- Tree-based models doesn't depend on scaling and Rank
- Non-tree-based models hugely depend on scaling and Rank
scaling
To [0,1]
1
2
3sklearn.preprocessing.MinMaxScaler
x = (x-min()) / (x.max() - x.min())To mean=0,std=1
1
2sklearn.preprocessing.StandardScaler
x = (x - x.mean()) / x.std()
Rank
1 | from scipy.stats import rankdata |
Other
You can apply log transformation through your data, or there's another possibility. You can extract a square root of the data. Both these transformations can be useful because they drive too big values closer to the features' average value. Along with this, the values near zero are becoming a bit more distinguishable. Despite the simplicity, one of these transformations can improve your neural network's results significantly. 1
2np.log(1+x)
np.sqrt(x+2/3)
outlier
1 | UPPERBOUND,LOWERBOUND = np.percentile(x,[1,99]) |
Feature generation
Sometimes, we can engineer these features using prior knowledge and logic. Sometimes we have to dig into the data, create and check hypothesis, and use this derived knowledge and our intuition to derive new features.
- prior knowledge
It is useful to know that adding, multiplications, divisions, and other features interactions can be of help not only for linear models. For example, although gradient within decision tree is a very powerful model, it still experiences difficulties with approximation of multiplications and divisions. And adding size features explicitly can lead to a more robust model with less amount of trees.


This feature can help the model utilize the differences in people's perception of these prices. Also, we can find similar patterns in tasks which require distinguishing between a human and a robot.

- EDA(Exploratory data analysis)
Category feature
- Label and Frequency encodings are often used for tree- based models
- One-hot encoding is often used for non-tree-based models
- Interactions of categorical features can help linear models and KNN
Ordinal features
Values in ordinal features are sorted in some meaningful order - Ticket class: 1,2,3 - Driver’s license: A, B, C, D - Education: kindergarden, school, undergraduate, bachelor, master, doctoral
- Label encoding maps categories to numbers
1
2
3from sklearn import preprocessing
encoder = preprocessing.LabelEncoder()
encoder.fit(categorical_features) - Frequency encoding maps categories to their frequencies
1
2
3encoding = titanic.groupby(‘Embarked’).size()
encoding = encoding/len(titanic)
titanic["enc"] = titanic.Embarked.map(encoding)
Datetime
- Periodicity Day number in week, month, season, year second, minute, hour.
- Time since
- Row-independent moment For example: since 00:00:00 UTC, 1 January 1970;
- Row-dependent important moment Number of days left until next holidays / time passed after last holiday.
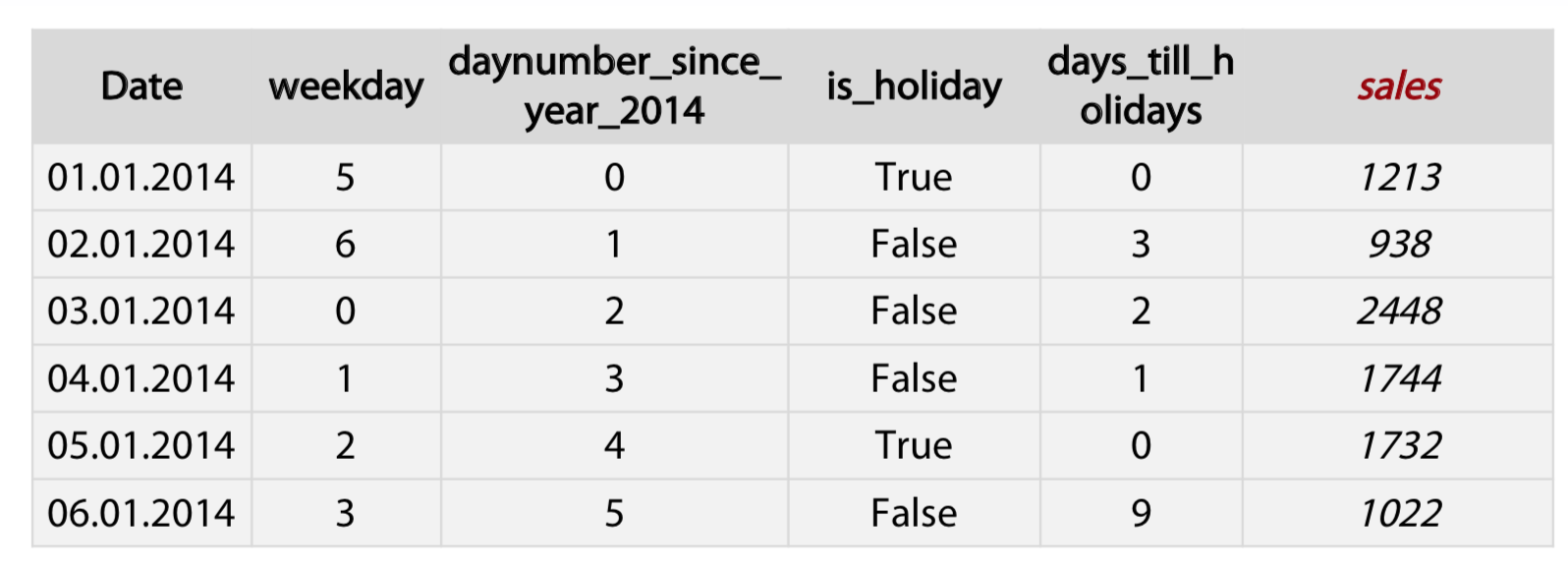
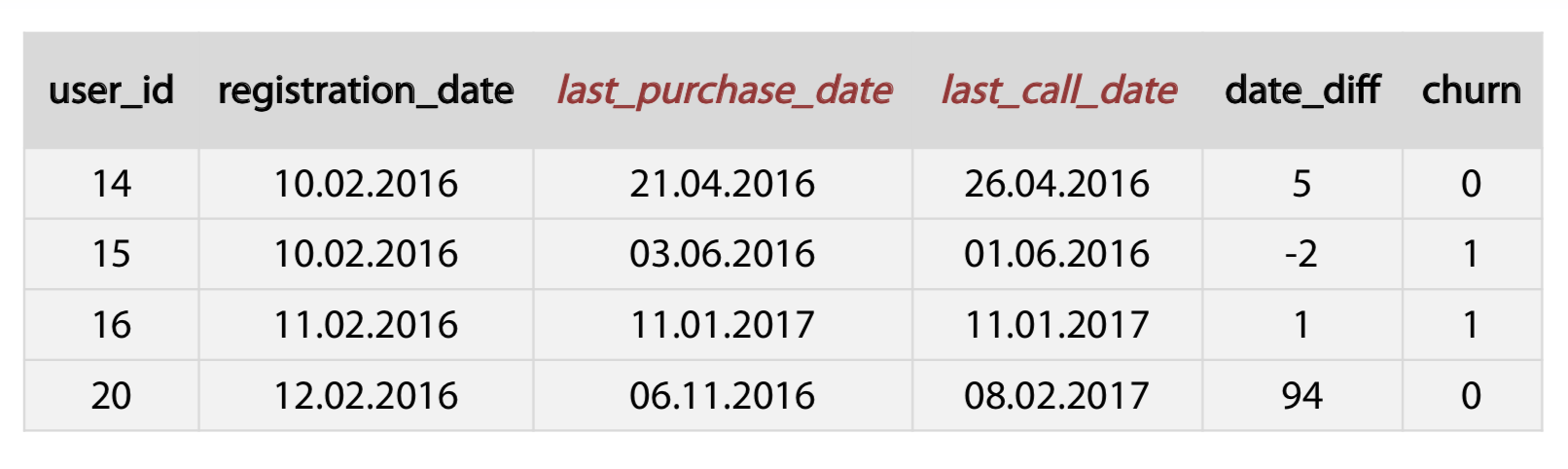
- Difference between dates
- datetime_feature_1 - datetime_feature_2
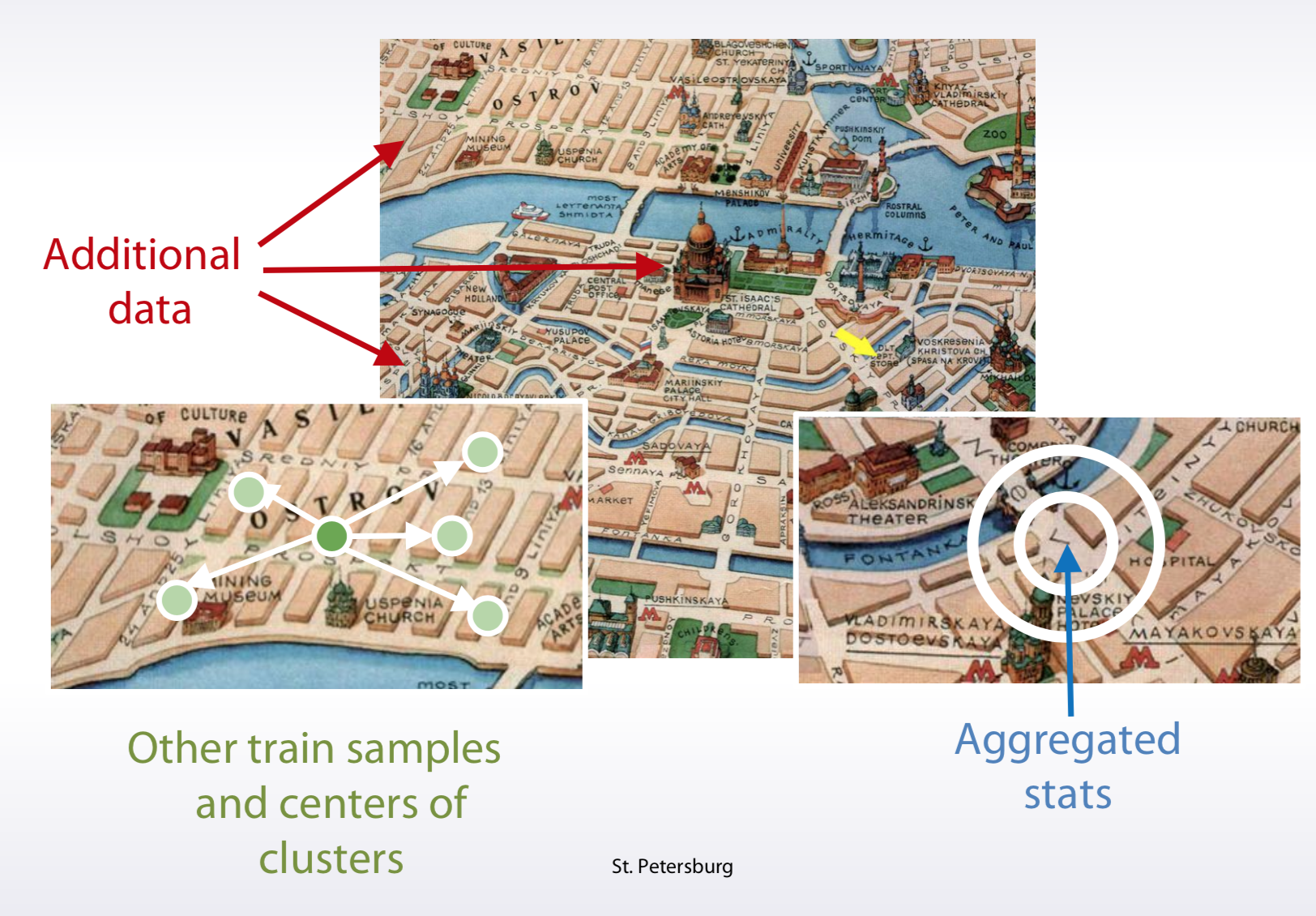
Coordinates
- Interesting places from train/test data or additional data Generally, you can calculate distances to important points on the map. You can extract interesting points on the map from your trained test data.
- Centers of clusters
- Aggregated statistics use coordinates is to calculate aggregated statistics for objects surrounding area.
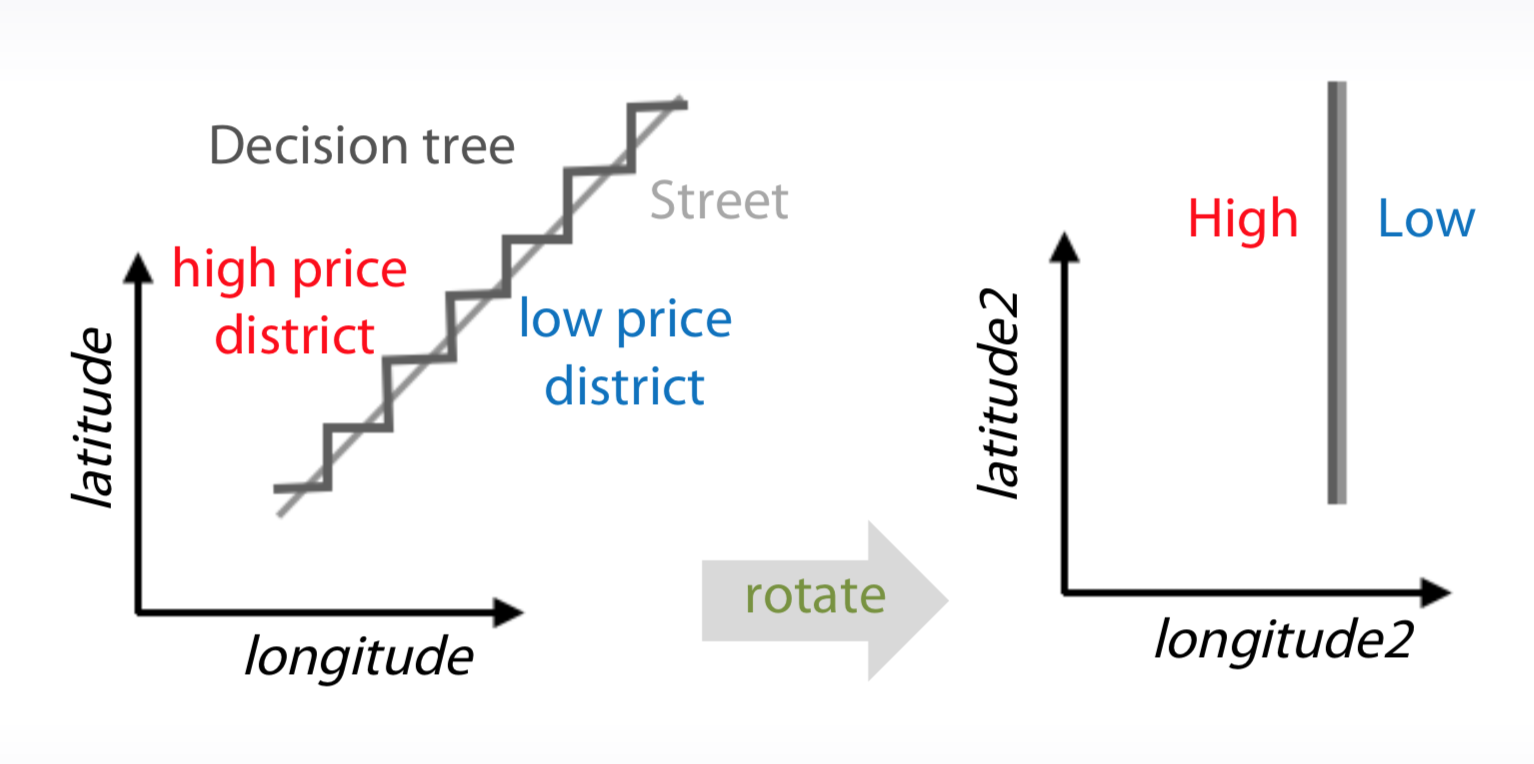
- If you train decision trees from them, you can add slightly rotated coordinates is new features. And this will help a model make more precise selections on the map.
Missing Data
Fillna approaches
- -999, -1, etc
- mean, median
- Reconstruct value
- we should be very careful with replacing missing values before our feature generation
- It can be beneficial to change the missing values or categories which present in the test data but do not present in the train data. The intention for doing so appeals to the fact that the model which didn't have that category in the train data will eventually treat it randomly.
Isnull feature
| 0.1 | False |
| 0.2 | False |
| NaN | True |
Feature extraction
Texts
- Preprocessing
- Lowercase, stemming, lemmarization, stopwords
1
2
3Lowercase: Very, very -> very,very
lemmarization: I had a car -> I have a car
stopwords: sklearn.feature_extraction.text.CountVectorizer(max_df)
- Lowercase, stemming, lemmarization, stopwords
- Bag of words
1
2
3
4
5
6# Design the Vocabulary
# Create Document Vectors
"it was the worst of times" = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
"it was the age of wisdom" = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
"it was the age of foolishness" = [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]- Huge vectors
- Ngrams can help to use local context
1
2from sklearn.feature_extraction.text import CountVectorizer
# Ngram_range, analyzer - TF-IDF can be of use as postprocessing > 如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率(另一说:TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数)。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大(见后续公式),则说明词条t具有很好的类别区分能力。
1
2
3
4
5
6
7## Term frequency
tf = 1 / x.sum(axis=1) [:,None]
x = x * tf
## Inverse Document Frequency
idf = np.log(x.shape[0] / (x > 0).sum(0)) x = x * idf
from sklearn.feature_extraction.text import TfidfVectorizer
- Word2vec
- Relatively small vectors
- Pretrained models
Images
- Features can be extracted from different layers
- Careful choosing of pretrained network can help
- Finetuning allows to refine pretrained models
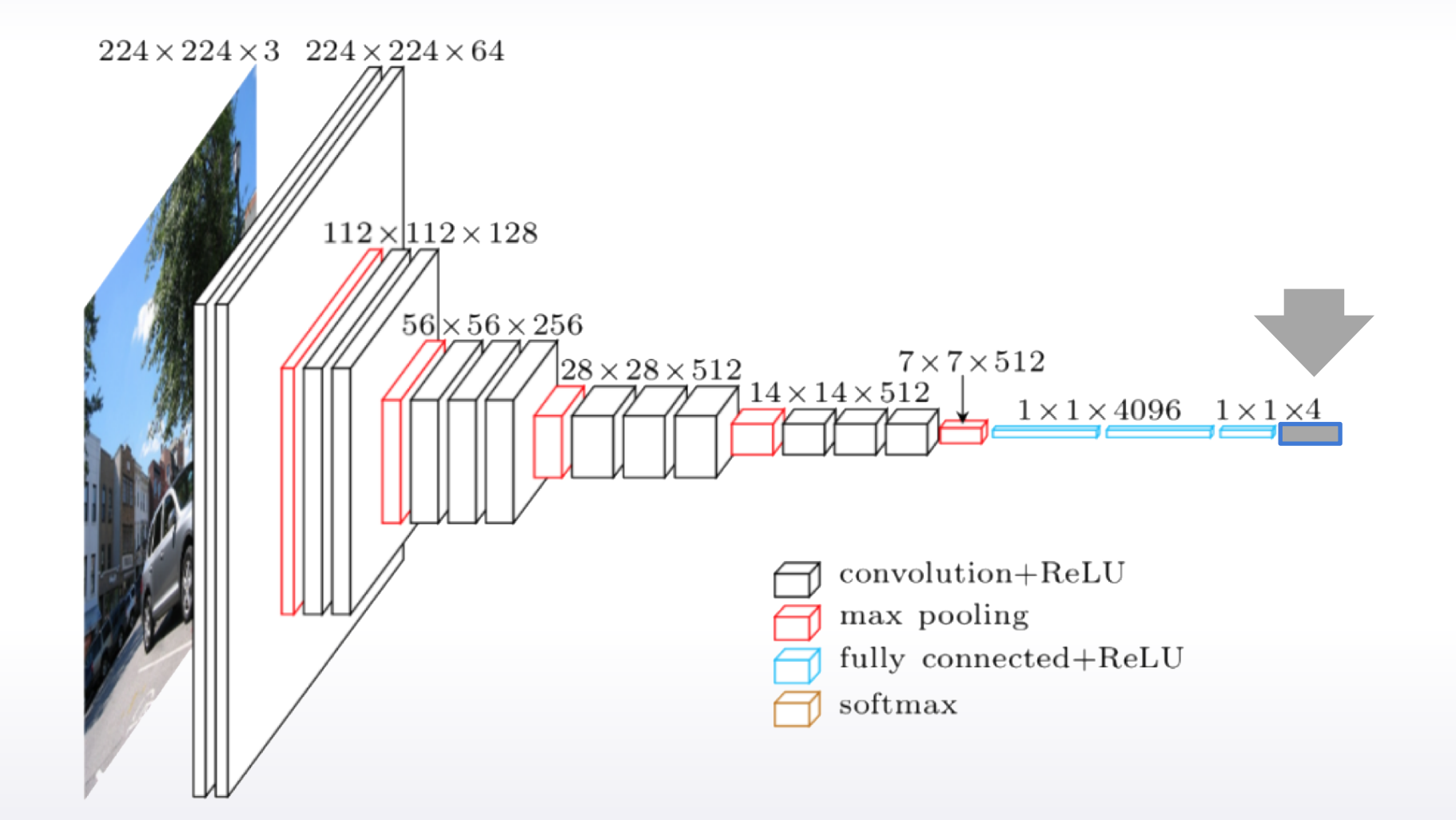
- Data augmentation can improve the model
