Assignment 2: Optimal Policies with Dynamic Programming
Welcome to Assignment 2. This notebook will help you understand: - Policy Evaluation and Policy Improvement. - Value and Policy Iteration. - Bellman Equations.
Gridworld City
Gridworld City, a thriving metropolis with a booming technology industry, has recently experienced an influx of grid-loving software engineers. Unfortunately, the city's street parking system, which charges a fixed rate, is struggling to keep up with the increased demand. To address this, the city council has decided to modify the pricing scheme to better promote social welfare. In general, the city considers social welfare higher when more parking is being used, the exception being that the city prefers that at least one spot is left unoccupied (so that it is available in case someone really needs it). The city council has created a Markov decision process (MDP) to model the demand for parking with a reward function that reflects its preferences. Now the city has hired you — an expert in dynamic programming — to help determine an optimal policy.
Preliminaries
You'll need two imports to complete this assigment: - numpy: The fundamental package for scientific computing with Python. - tools: A module containing an environment and a plotting function.
There are also some other lines in the cell below that are used for grading and plotting — you needn't worry about them.
In this notebook, all cells are locked except those that you are explicitly asked to modify. It is up to you to decide how to implement your solution in these cells, but please do not import other libraries — doing so will break the autograder.
1 | %matplotlib inline |
<Figure size 432x288 with 0 Axes>In the city council's parking MDP, states are nonnegative integers indicating how many parking spaces are occupied, actions are nonnegative integers designating the price of street parking, the reward is a real value describing the city's preference for the situation, and time is discretized by hour. As might be expected, charging a high price is likely to decrease occupancy over the hour, while charging a low price is likely to increase it.
For now, let's consider an environment with three parking spaces and three price points. Note that an environment with three parking spaces actually has four states — zero, one, two, or three spaces could be occupied.
1 | # --------------- |
The value function is a one-dimensional array where the \(i\)-th entry gives the value of \(i\) spaces being occupied.
1 | V |
array([0., 0., 0., 0.])We can represent the policy as a two-dimensional array where the \((i, j)\)-th entry gives the probability of taking action \(j\) in state \(i\).
1 | pi |
array([[0.33333333, 0.33333333, 0.33333333],
[0.33333333, 0.33333333, 0.33333333],
[0.33333333, 0.33333333, 0.33333333],
[0.33333333, 0.33333333, 0.33333333]])1 | pi[0] = [0.75, 0.11, 0.14] |
pi(A=0|S=0) = 0.75 pi(A=1|S=0) = 0.11 pi(A=2|S=0) = 0.14
pi(A=0|S=1) = 0.33 pi(A=1|S=1) = 0.33 pi(A=2|S=1) = 0.33
pi(A=0|S=2) = 0.33 pi(A=1|S=2) = 0.33 pi(A=2|S=2) = 0.33
pi(A=0|S=3) = 0.33 pi(A=1|S=3) = 0.33 pi(A=2|S=3) = 0.33 1 | V[0] = 1 |
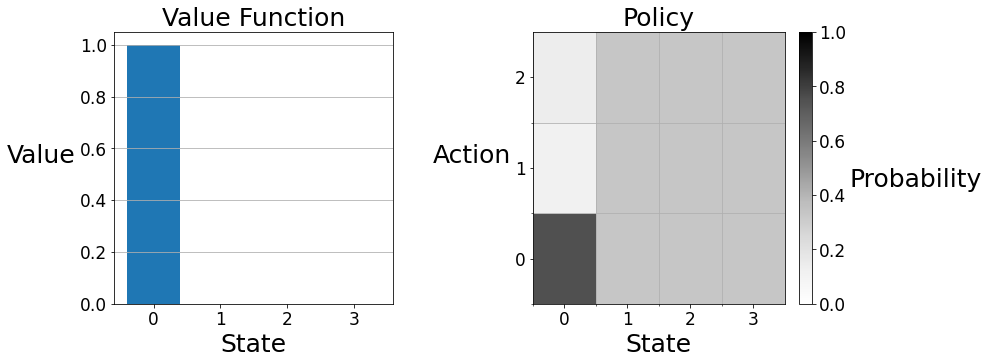
We can visualize a value function and policy with the plot function in the tools module. On the left, the value function is displayed as a barplot. State zero has an expected return of ten, while the other states have an expected return of zero. On the right, the policy is displayed on a two-dimensional grid. Each vertical strip gives the policy at the labeled state. In state zero, action zero is the darkest because the agent's policy makes this choice with the highest probability. In the other states the agent has the equiprobable policy, so the vertical strips are colored uniformly.
You can access the state space and the action set as attributes of the environment.
1 | env.S |
[0, 1, 2, 3]1 | env.A |
[0, 1, 2]You will need to use the environment's transitions method to complete this assignment. The method takes a state and an action and returns a 2-dimensional array, where the entry at \((i, 0)\) is the reward for transitioning to state \(i\) from the current state and the entry at \((i, 1)\) is the conditional probability of transitioning to state \(i\) given the current state and action.
1 | state = 3 |
array([[1. , 0.12390437],
[2. , 0.15133714],
[3. , 0.1848436 ],
[2. , 0.53991488]])1 | for sp, (r, p) in enumerate(transitions): |
p(S'=0, R=1.0 | S=3, A=1) = 0.12
p(S'=1, R=2.0 | S=3, A=1) = 0.15
p(S'=2, R=3.0 | S=3, A=1) = 0.18
p(S'=3, R=2.0 | S=3, A=1) = 0.54Section 1: Policy Evaluation
You're now ready to begin the assignment! First, the city council would like you to evaluate the quality of the existing pricing scheme. Policy evaluation works by iteratively applying the Bellman equation for \(v_{\pi}\) to a working value function, as an update rule, as shown below.
\[\large v(s) \leftarrow \sum_a \pi(a | s) \sum_{s', r} p(s', r | s, a)[r + \gamma v(s')]\] This update can either occur "in-place" (i.e. the update rule is sequentially applied to each state) or with "two-arrays" (i.e. the update rule is simultaneously applied to each state). Both versions converge to \(v_{\pi}\) but the in-place version usually converges faster. In this assignment, we will be implementing all update rules in-place, as is done in the pseudocode of chapter 4 of the textbook.
We have written an outline of the policy evaluation algorithm described in chapter 4.1 of the textbook. It is left to you to fill in the bellman_update function to complete the algorithm.
1 | # lock |
1 | # ----------- |
The cell below uses the policy evaluation algorithm to evaluate the city's policy, which charges a constant price of one.
1 | # -------------- |
[80.04173399 81.65532303 83.37394007 85.12975566 86.87174913 88.55589131
90.14020422 91.58180605 92.81929841 93.78915889 87.77792991]1 | # ----------- |
You can use the plot function to visualize the final value function and policy.
1 | # lock |
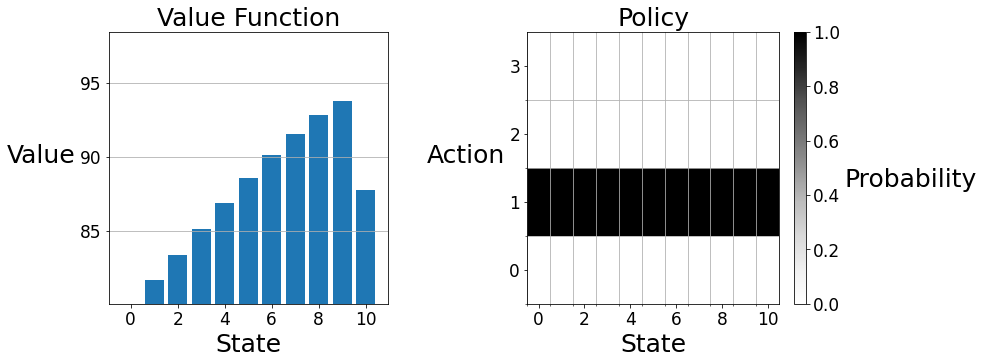
Observe that the value function qualitatively resembles the city council's preferences — it monotonically increases as more parking is used, until there is no parking left, in which case the value is lower. Because of the relatively simple reward function (more reward is accrued when many but not all parking spots are taken and less reward is accrued when few or all parking spots are taken) and the highly stochastic dynamics function (each state has positive probability of being reached each time step) the value functions of most policies will qualitatively resemble this graph. However, depending on the intelligence of the policy, the scale of the graph will differ. In other words, better policies will increase the expected return at every state rather than changing the relative desirability of the states. Intuitively, the value of a less desirable state can be increased by making it less likely to remain in a less desirable state. Similarly, the value of a more desirable state can be increased by making it more likely to remain in a more desirable state. That is to say, good policies are policies that spend more time in desirable states and less time in undesirable states. As we will see in this assignment, such a steady state distribution is achieved by setting the price to be low in low occupancy states (so that the occupancy will increase) and setting the price high when occupancy is high (so that full occupancy will be avoided).
Section 2: Policy Iteration
Now the city council would like you to compute a more efficient policy using policy iteration. Policy iteration works by alternating between evaluating the existing policy and making the policy greedy with respect to the existing value function. We have written an outline of the policy iteration algorithm described in chapter 4.3 of the textbook. We will make use of the policy evaluation algorithm you completed in section 1. It is left to you to fill in the q_greedify_policy function, such that it modifies the policy at \(s\) to be greedy with respect to the q-values at \(s\), to complete the policy improvement algorithm.
1 | def improve_policy(env, V, pi, gamma): |
1 | # ----------- |
1 | # -------------- |
1 | # ----------- |
When you are ready to test the policy iteration algorithm, run the cell below.
1 | env = tools.ParkingWorld(num_spaces=10, num_prices=4) |
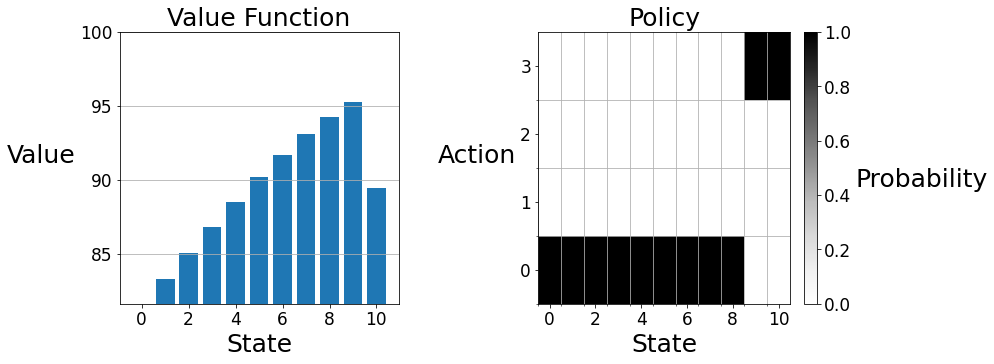
You can use the plot function to visualize the final value function and policy.
1 | tools.plot(V, pi) |
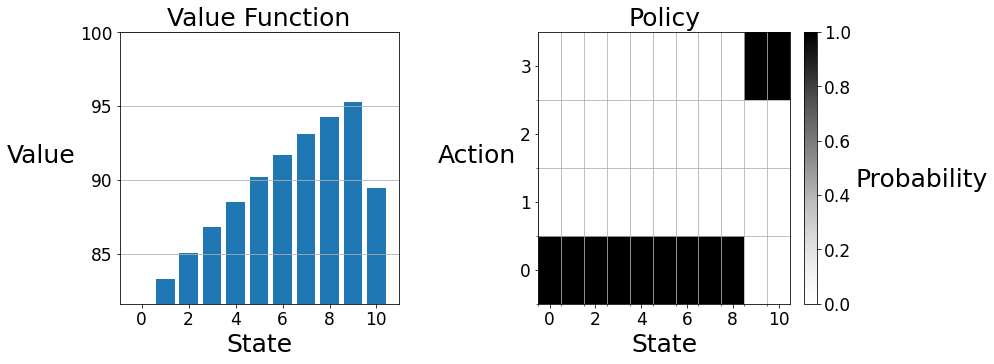
You can check the value function (rounded to one decimal place) and policy against the answer below:
State \(\quad\quad\) Value \(\quad\quad\) Action
0 \(\quad\quad\quad\;\) 81.6 \(\quad\quad\;\) 0
1 \(\quad\quad\quad\;\) 83.3 \(\quad\quad\;\) 0
2 \(\quad\quad\quad\;\) 85.0 \(\quad\quad\;\) 0
3 \(\quad\quad\quad\;\) 86.8 \(\quad\quad\;\) 0
4 \(\quad\quad\quad\;\) 88.5 \(\quad\quad\;\) 0
5 \(\quad\quad\quad\;\) 90.2 \(\quad\quad\;\) 0
6 \(\quad\quad\quad\;\) 91.7 \(\quad\quad\;\) 0
7 \(\quad\quad\quad\;\) 93.1 \(\quad\quad\;\) 0
8 \(\quad\quad\quad\;\) 94.3 \(\quad\quad\;\) 0
9 \(\quad\quad\quad\;\) 95.3 \(\quad\quad\;\) 3
10 \(\quad\quad\;\;\,\,\) 89.5 \(\quad\quad\;\) 3
Section 3: Value Iteration
The city has also heard about value iteration and would like you to implement it. Value iteration works by iteratively applying the Bellman optimality equation for \(v_{\ast}\) to a working value function, as an update rule, as shown below.
\[\large v(s) \leftarrow \max_a \sum_{s', r} p(s', r | s, a)[r + \gamma v(s')]\] We have written an outline of the value iteration algorithm described in chapter 4.4 of the textbook. It is left to you to fill in the bellman_optimality_update function to complete the value iteration algorithm.
1 | def value_iteration(env, gamma, theta): |
1 | # ----------- |
1 | # -------------- |
1 | # ----------- |
When you are ready to test the value iteration algorithm, run the cell below.
1 | env = tools.ParkingWorld(num_spaces=10, num_prices=4) |
You can use the plot function to visualize the final value function and policy.
1 | tools.plot(V, pi) |
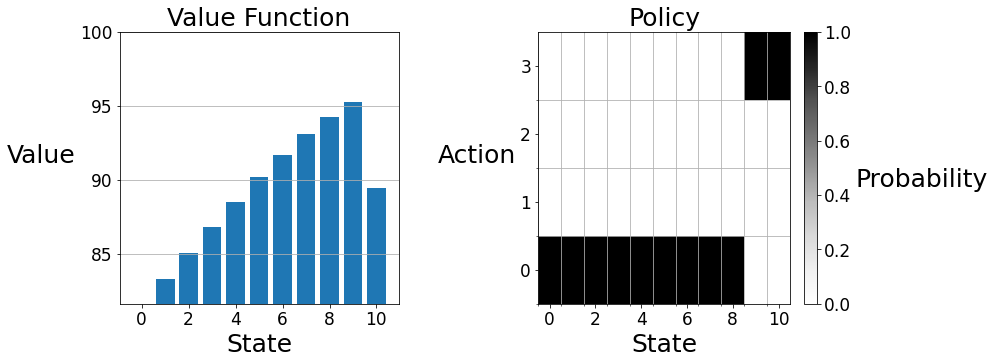
You can check your value function (rounded to one decimal place) and policy against the answer below:
State \(\quad\quad\) Value \(\quad\quad\) Action
0 \(\quad\quad\quad\;\) 81.6 \(\quad\quad\;\) 0
1 \(\quad\quad\quad\;\) 83.3 \(\quad\quad\;\) 0
2 \(\quad\quad\quad\;\) 85.0 \(\quad\quad\;\) 0
3 \(\quad\quad\quad\;\) 86.8 \(\quad\quad\;\) 0
4 \(\quad\quad\quad\;\) 88.5 \(\quad\quad\;\) 0
5 \(\quad\quad\quad\;\) 90.2 \(\quad\quad\;\) 0
6 \(\quad\quad\quad\;\) 91.7 \(\quad\quad\;\) 0
7 \(\quad\quad\quad\;\) 93.1 \(\quad\quad\;\) 0
8 \(\quad\quad\quad\;\) 94.3 \(\quad\quad\;\) 0
9 \(\quad\quad\quad\;\) 95.3 \(\quad\quad\;\) 3
10 \(\quad\quad\;\;\,\,\) 89.5 \(\quad\quad\;\) 3
In the value iteration algorithm above, a policy is not explicitly maintained until the value function has converged. Below, we have written an identically behaving value iteration algorithm that maintains an updated policy. Writing value iteration in this form makes its relationship to policy iteration more evident. Policy iteration alternates between doing complete greedifications and complete evaluations. On the other hand, value iteration alternates between doing local greedifications and local evaluations.
1 | def value_iteration2(env, gamma, theta): |
You can try the second value iteration algorithm by running the cell below.
1 | env = tools.ParkingWorld(num_spaces=10, num_prices=4) |
Wrapping Up
Congratulations, you've completed assignment 2! In this assignment, we investigated policy evaluation and policy improvement, policy iteration and value iteration, and Bellman updates. Gridworld City thanks you for your service!