Unsupervised representation learning with deep convolutional generative adversarial network
- Category: Article
- Created: January 24, 2022 5:31 PM
- Status: Open
- URL: https://arxiv.org/pdf/1511.06434.pdf
- Updated: February 15, 2022 6:49 PM
Background
- In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning.
- We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning.
Methods
Architecture guidelines for stable Deep Convolutional GANs
- Replace any pooling layers with strided convolutions (discriminator) and fractional-strided convolutions (generator).
- Use batchnorm in both the generator and the discriminator.
- Remove fully connected hidden layers for deeper architectures.
- Use ReLU activation in generator for all layers except for the output, which uses Tanh.
- Use LeakyReLU activation in the discriminator for all layers.
Generator
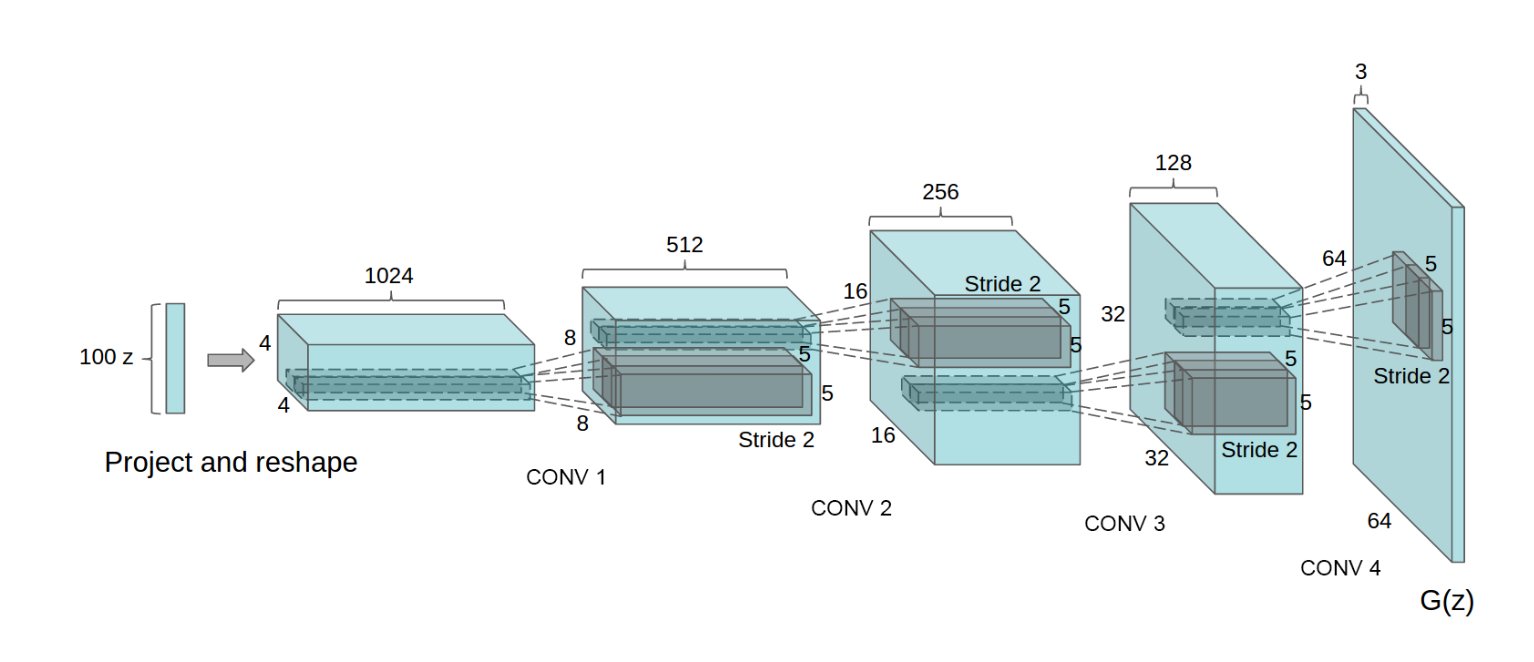
DCGAN generator used for LSUN scene modeling. A 100 dimensional uniform distribu- tion Z is projected to a small spatial extent convolutional representation with many feature maps. A series of four fractionally-strided convolutions (in some recent papers, these are wrongly called deconvolutions) then convert this high level representation into a 64 × 64 pixel image. Notably, no fully connected or pooling layers are used.
1 | # Generator Code |
Descriminator
The DCGAN paper mentions it is a good practice to use strided convolution rather than pooling to downsample because it lets the network learn its own pooling function. Also batch norm and leakyRelu functions promote healthy gradient flow which is critical for the learning process of both \(G\) and \(D\).
1 | class Discriminator(nn.Module): |