InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
- Category: Article
- Created: February 8, 2022 7:26 PM
- Status: Open
- URL: https://arxiv.org/pdf/1606.03657.pdf
- Updated: February 15, 2022 6:12 PM
Highlights
- Adversarial Network that is able to learn disentangled representations in a completely unsupervised manner.
- In this paper, we present a simple modification to the generative adversarial network objective that encourages it to learn interpretable and meaningful representations.
Methods
Mutual Information
- In information theory, mutual information between \(X\) and \(Y\) , \(I(X,Y)\), measures the “amount of information” learned from knowledge of random variable \(Y\) about the other random variable \(X\).
- The mutual information can be expressed as the difference of two entropy terms:
\[ I(X ; Y)=H(X)-H(X \mid Y)=H(Y)-H(Y \mid X) \]
- This definition has an intuitive interpretation: \(I(X,Y)\) is the reduction of uncertainty in \(X\) when \(Y\) is observed. If \(X\) and are independent, then \(I(X,Y) = 0\), because knowing one variable reveals nothing about the other.
Mutual Information for Inducing Latent Codes
- \(z\) : which is treated as source of incompressible noise;
- \(c\) : which we will call the latent code and will target the salient structured semantic features of the data distribution. ****
- we provide the generator network with both the incompressible noise z and the latent code \(c\), so the form of the generator becomes \(G(z,c)\).
- we propose an information-theoretic regularization: there should be high mutual information between latent codes \(c\) and generator distribution \(G(z,c)\). Thus \(I(c, G(z,c))\) should be high.
Variational Mutual Information Maximization
Hence, InfoGAN is defined as the following minimax game with a variational regularization of mutual information
\[ \min _{G, Q} \max _{D} V_{\text {InfoGAN }}(D, G, Q)=V(D, G)-\lambda L_{I}(G, Q) \]
In practice, the mutual information term \(I(c, G(z,c))\) is hard to maximize directly as it requires access to the posterior \(P(x|z)\). Fortunately we can obtain a lower bound of it by defining an auxiliary distribution \(Q(c|x)\) to approximate \(P(c|x)\).
\[ \begin{aligned}I(c ; G(z, c)) &=H(c)-H(c \mid G(z, c)) \\&=\mathbb{E}_{x \sim G(z, c)}\left[\mathbb{E}_{c^{\prime} \sim P(c \mid x)}\left[\log P\left(c^{\prime} \mid x\right)\right]\right]+H(c) \\&=\mathbb{E}_{x \sim G(z, c)}[\underbrace{D_{\mathrm{KL}}(P(\cdot \mid x) \| Q(\cdot \mid x))}_{\geq 0}+\mathbb{E}_{c^{\prime} \sim P(c \mid x)}\left[\log Q\left(c^{\prime} \mid x\right)\right]]+H(c) \\& \geq \mathbb{E}_{x \sim G(z, c)}\left[\mathbb{E}_{c^{\prime} \sim P(c \mid x)}\left[\log Q\left(c^{\prime} \mid x\right)\right]\right]+H(c)\end{aligned} \]
In practice, we parametrize the auxiliary distribution \(Q\) as a neural network. In most experiments, \(Q\) and \(D\) share all convolutional layers and there is one final fully connected layer to output parameters for the conditional distribution \(Q(c|x)\), which means InfoGAN only adds a negligible computation cost to GAN.
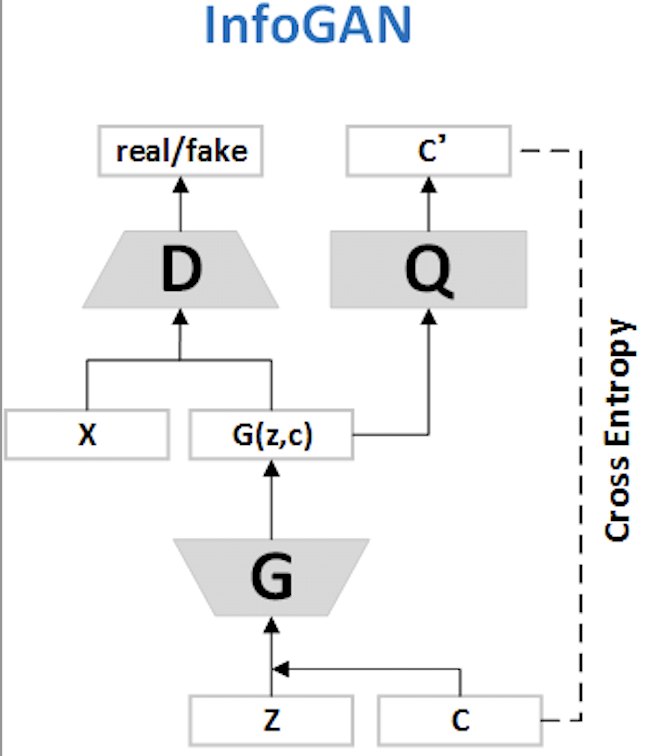
Code
- reference from https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/infogan/infogan.py
Generator
1 | class Generator(nn.Module): |
Discriminator
1 | class Discriminator(nn.Module): |
Training
1 | for epoch in range(opt.n_epochs): |